Genoma humano: qué es, estructura, funciones y proyectos clave
Descubre el genoma humano: estructura, funciones, proyectos clave (PGH, ENCODE), avances y aplicaciones médicas. Explicación clara y actualizada.
El genoma humano está almacenado en 23 pares de cromosomas del núcleo celular y en el pequeño ADN mitocondrial. En la actualidad se sabe mucho sobre las secuencias de ADN que se encuentran en nuestros cromosomas. Ahora se sabe en parte lo que hace el ADN. La aplicación de estos conocimientos en la práctica no ha hecho más que empezar.
El Proyecto Genoma Humano (PGH) produjo una secuencia de referencia que se utiliza en todo el mundo en biología y medicina. Nature publicó el informe del proyecto, financiado con fondos públicos, y Science publicó el artículo de Celera. Estos artículos describen cómo se produjo el borrador de la secuencia y ofrecen un análisis de la misma. En 2003 y 2005 se anunciaron borradores mejorados que completaron hasta ≈92% de la secuencia.
El último proyecto ENCODE estudia la forma en que se controlan los genes.
Galería de imágenes
5 Imágenes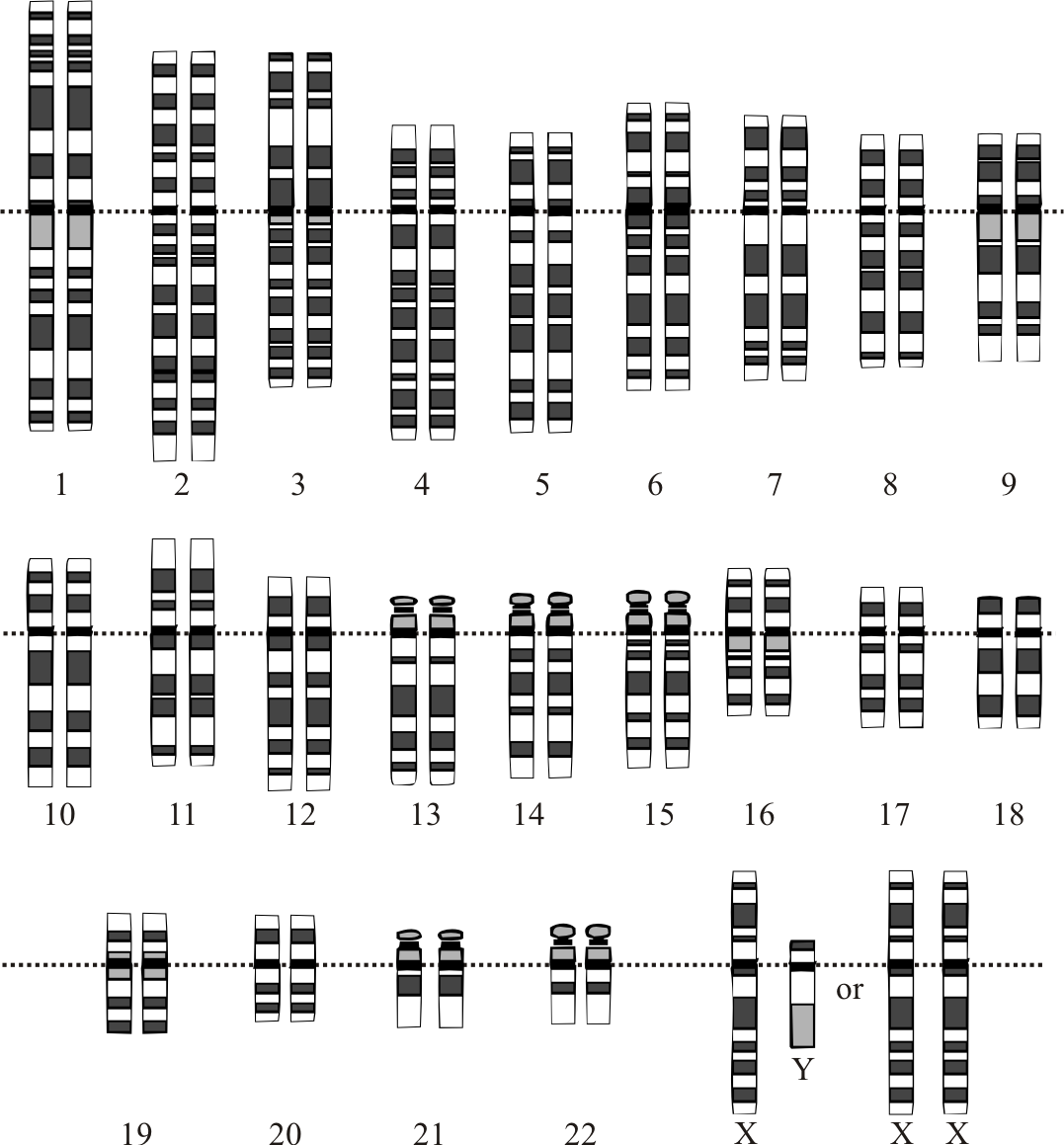


Qué entendemos por genoma humano
El genoma humano es el conjunto completo de información genética de una persona, expresada en moléculas de ADN. En términos prácticos se suele hablar de la secuencia de referencia —una versión representativa del genoma que sirve para comparar y mapear datos genómicos—, pero cada individuo tiene pequeñas diferencias respecto a esa referencia (variantes genéticas).
Estructura física y tamaño
Organización: la mayor parte del material genético se encuentra en el núcleo, distribuido en 23 pares de cromosomas (22 autosomas más los cromosomas sexuales). Además existe ADN mitocondrial (ADNmt), una molécula circular más pequeña que reside en las mitocondrias y que se hereda mayoritariamente por vía materna.
- Tamaño: la secuencia haploide del genoma humano contiene aproximadamente 3.200 millones de pares de bases (≈3,2 Gb). En una célula diploide hay el doble de bases.
- Genes: hay entre ≈20.000 y 25.000 genes que codifican proteínas; además existen miles de genes que producen ARN no codificante (microARN, lncRNA, etc.).
- Porcentaje codificante: sólo alrededor del 1–2% del genoma codifica proteínas. El resto incluye regiones reguladoras, intrones, secuencias repetitivas (transposones, LINEs, SINEs), telómeros y centrómeros.
- ADN mitocondrial: tiene ~16.6 kb (≈16.569 pares de bases) y codifica genes esenciales para la respiración celular.
Funciones principales del genoma
- Coding: los exones de genes codifican las proteínas que realizan funciones estructurales, enzimáticas y regulatorias en la célula.
- Regulación génica: promotores, enhancers, silencers y otros elementos controlan cuándo, dónde y cuánto se expresa un gen. Proyectos como ENCODE han identificado y caracterizado muchos de estos elementos regulatorios.
- ARN no codificante: ARN con funciones regulatorias y estructurales (p. ej., microARNs que regulan traducción, lncRNAs implicados en control de cromatina).
- Estructura y estabilidad cromosómica: telómeros protegen los extremos cromosómicos; los centrómeros son esenciales para la separación cromosómica en la mitosis.
- Variación genética: polimorfismos de un solo nucleótido (SNPs), variantes estructurales y deleciones/duplicaciones generan diversidad entre individuos y pueden influir en la salud y en rasgos fenotípicos.
- Epigenética: modificaciones químicas del ADN (metilación) y de las histonas regulan la accesibilidad del ADN y la expresión génica sin cambiar la secuencia.
Proyectos clave y avances históricos
- Proyecto Genoma Humano (PGH): iniciativa pública (1990–2003) que produjo la primera secuencia de referencia y un borrador público amplio; sus resultados se publicaron, entre otras, en Nature.
- Celera Genomics: empresa privada que publicó un análisis complementario en Science, usando una estrategia diferente de ensamblaje y secuenciación.
- Mejoras posteriores (2003–2005): se anunciaron versiones más completas que alcanzaron aproximadamente ≈92% de la secuencia, corrigiendo y rellenando huecos del borrador inicial.
- ENCODE: proyecto dedicado a identificar elementos funcionales y regulatorios del genoma; ha revelado que gran parte del ADN tiene actividad bioquímica o papel regulador.
- Telomere-to-Telomere (T2T): consorcio que, en 2021–2022, publicó una versión prácticamente completa (CHM13) que resolvió regiones muy repetitivas y centrómeros que faltaban en la referencia original.
- Human Pangenome Reference Consortium (HPRC): proyecto para construir una referencia que represente mejor la diversidad genética humana, evitando el sesgo de usar una única secuencia de referencia.
Herramientas y tecnologías
- Sanger: método clásico usado en el PGH para secuenciar fragmentos largos con alta precisión.
- Secuenciación masiva (NGS): tecnologías de segunda generación (p. ej. Illumina) que abarataron enormemente el coste y permitieron secuenciar muchos genomas.
- Lecturas largas: tecnologías como PacBio y Oxford Nanopore permiten resolver regiones repetitivas y ensamblar genomas más completos (clave para el proyecto T2T).
- Bioinformática: herramientas para ensamblaje, alineamiento, anotación y análisis de variantes son esenciales para convertir datos de secuencia en conocimiento biológico y clínico.
Aplicaciones, beneficios y retos éticos
El conocimiento del genoma ha impulsado la medicina (diagnóstico genético, pruebas prenatales, oncología de precisión, farmacogenómica), la biotecnología y la investigación sobre el origen y la evolución humana. Sin embargo, plantea retos:
- Privacidad y seguridad de los datos genómicos: riesgos de reidentificación y uso indebido.
- Desigualdad en el acceso a pruebas y terapias basadas en genómica.
- Implicaciones éticas de la edición genética (CRISPR), selección genética y manipulación germinal.
- Necesidad de referencias más diversas para evitar sesgos en investigación y medicina.
Perspectivas futuras
La genómica avanza hacia referencias más completas y representativas (pangenomas), mayor integración de datos epigenómicos y de expresión, y aplicaciones clínicas más precisas. El reto es traducir este conocimiento en beneficios sanitarios equitativos, manteniendo altos estándares éticos y de protección de datos.

ADN y proteínas
El genoma humano contiene poco más de 20.000 genes que codifican proteínas, mucho menos de lo que se esperaba. De hecho, sólo un 1,5% del genoma codifica proteínas, mientras que el resto consiste en genes de ARN no codificante, secuencias reguladoras e intrones.
Sin embargo, un solo gen puede producir una variedad de proteínas mediante el empalme de ARN. Un gen concreto de Drosophila (DSCAM) puede empalmarse alternativamente en 38.000 ARNm diferentes. Cada ARNm codifica una cadena peptídica diferente. Por lo tanto, el número de proteínas producidas es muy superior al número de genes codificantes.
Con el empalme del ARN y los cambios posteriores a la traducción del ARN, el número total de proteínas humanas únicas puede ser de unos pocos millones.
La idea de que la mayor parte del ADN es "basura" inútil es errónea. Al menos el 80% del genoma tiene funciones definidas.
Diferencias entre humanos y chimpancés
El animal vivo más parecido al ser humano es el chimpancé. El 98,4% del ADN es el mismo entre los humanos y los chimpancés. Sin embargo, esto sólo se aplica a los polimorfismos de un solo nucleótido, es decir, a los cambios en un solo par de bases. El cuadro completo es bastante diferente.
El borrador de la secuencia del genoma del chimpancé común se publicó en 2005. En él se mostraba que las regiones lo suficientemente similares como para ser alineadas entre sí representan 2.400 millones de los 3.164,7 millones de bases del genoma humano, es decir, el 75,8% del genoma.
Este 75,8% del genoma humano presenta un 1,23% de diferencia con el genoma del chimpancé en cuanto a polimorfismos de un solo nucleótido (SNP, por sus siglas en inglés: cambios de "letras" individuales de ADN en el genoma). Otro tipo de diferencias, denominadas "indels" (inserciones/deleciones) suponen otro ~3% de diferencia entre las secuencias alineables. Además, la variación en el número de copias de grandes segmentos (> 20 kb) de una secuencia de ADN similar aporta otro 2,7% de diferencia entre las dos especies. Por lo tanto, la similitud total de los genomas podría ser tan baja como un 70%.
Páginas relacionadas
Preguntas y respuestas
P: ¿Dónde se almacena el genoma humano?
R: El genoma humano está almacenado en 23 pares de cromosomas en el núcleo celular y en el pequeño ADN mitocondrial.
P: ¿Qué se sabe ahora sobre las secuencias de ADN de nuestros cromosomas?
R: Actualmente se sabe mucho sobre las secuencias de ADN de nuestros cromosomas.
P: ¿Qué es el Proyecto Genoma Humano?
R: El Proyecto Genoma Humano (PGH) es un proyecto que produjo una secuencia de referencia del genoma humano.
P: ¿Cuál es el porcentaje de la secuencia que se ha completado según los borradores mejorados?
R: Los borradores mejorados anunciados en 2003 y 2005 rellenaron hasta ≈92% de la secuencia.
P: ¿Cuál es el último proyecto que estudia la forma en que se controlan los genes?
R: El último proyecto, ENCODE, estudia la forma en que se controlan los genes.
P: Aunque la secuencia del genoma humano se ha determinado por completo, ¿se comprende totalmente?
R: No, la secuencia del genoma humano aún no se conoce por completo.
P: ¿Qué hace el ADN no codificante dentro del genoma?
R: El ADN no codificante dentro del genoma hace cosas importantes como regular la expresión de los genes, la organización de los cromosomas y las señales que controlan la herencia epigenética.
Artículos relacionados
Autor
AlegsaOnline.com Genoma humano: qué es, estructura, funciones y proyectos clave Leandro Alegsa
URL: https://es.alegsaonline.com/art/45651
Fuentes
- nature.com : "Initial sequencing and analysis of the human genome"
- doi.org : 10.1038/35057062
- pubmed.ncbi.nlm.nih.gov : 11237011
- sciencemag.org : "The sequence of the human genome"
- ui.adsabs.harvard.edu : 2001Sci...291.1304V
- doi.org : 10.1126/science.1058040
- pubmed.ncbi.nlm.nih.gov : 11181995
- nature.com : nature.com/articles/489046a?error=cookies_not_supported&code=d4894f7c-6c0e-44a7-aa48-3d32…
- bbc.co.uk : bbc.co.uk/news/health-19202141
- ui.adsabs.harvard.edu : 2004Natur.431..931H
- doi.org : 10.1038/nature03001
- pubmed.ncbi.nlm.nih.gov : 15496913
- nature.com : nature.com/articles/nature03001?error=cookies_not_supported&code=20c2dd82-9871-4421-b41a-…
- doi.org : 10.1126/science.337.6099.1159