Evolución dirigida: ingeniería de proteínas y diseño de enzimas
Evolución dirigida: ingeniería de proteínas y diseño de enzimas para biotecnología, innovación industrial y médica; técnicas in vivo e in vitro para enzimas más eficientes.
La evolución dirigida (ED) es una estrategia experimental para obtener proteínas y enzimas con propiedades mejoradas o nuevas, empleada en biotecnología industrial, medicina y investigación básica. Combina principios de la ingeniería de proteínas con procesos que imita la selección natural, pero acelerados y orientados hacia una función concreta.
Galería de imágenes
4 Imágenes


Ciclo básico de la evolución dirigida
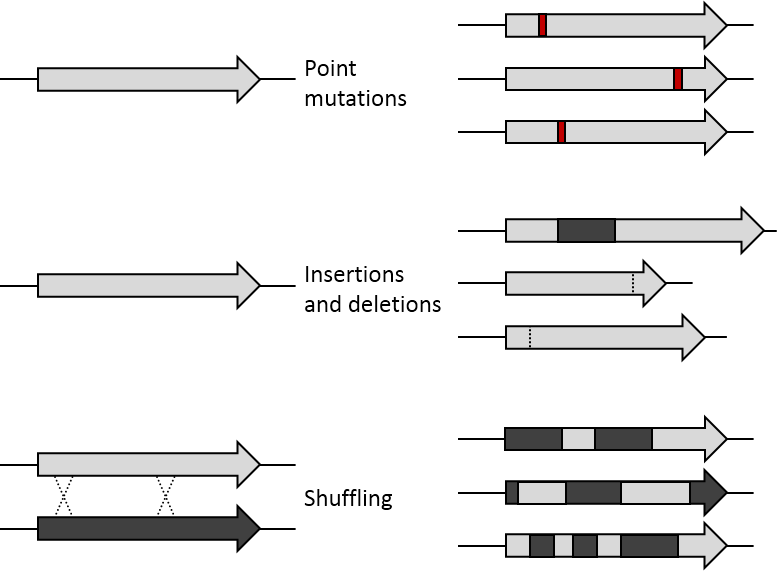
La idea esencial consiste en someter un gen a repetidas rondas de mutación para generar una biblioteca de variantes, y luego aplicar cribado o selección para aislar las variantes con la función deseada. Las variantes seleccionadas sirven como plantilla para la siguiente ronda, de modo que, mediante iteraciones, se acumulan cambios beneficiosos que mejoran la actividad, estabilidad, selectividad u otras propiedades de la proteína.
Formatos experimentales: in vivo e in vitro
La ED puede realizarse tanto in vivo como in vitro, y cada formato tiene ventajas:
- In vivo: durante la evolución in vivo, cada célula (habitualmente bacterias o levaduras) se transforma con un plásmido que contiene un miembro distinto de la biblioteca. Sólo el gen de interés difiere entre las células; el resto del genoma se mantiene constante. Las células expresan la proteína en su citoplasma o en su superficie, donde se puede comprobar su función. Este formato permite seleccionar propiedades en un contexto celular, útil cuando la proteína evolucionada se va a usar en organismos vivos.
- In vitro: sin células, la ED emplea la traducción de la transcripción in vitro para producir proteínas o ARN libres en solución o dentro de microgotas artificiales. Permite explorar más condiciones experimentales (por ejemplo, altas temperaturas o presencia de disolventes orgánicos), expresar proteínas tóxicas para células y construir bibliotecas mucho más grandes (hasta 10 15) porque no es necesario insertar el ADN en células huésped.
Métodos comunes para generar variabilidad
La diversidad genética de las bibliotecas se obtiene mediante varias técnicas:
- Mutagénesis aleatoria (p. ej. error-prone PCR): introduce errores puntuales distribuidos a lo largo del gen para explorar cambios locales.
- Recombination o DNA shuffling: fragmentación y recombinación de variantes para combinar cambios beneficiosos de distintos antecesores.
- Mutagénesis dirigida o saturación de posiciones: se mutan posiciones específicas (sitio a sitio) para explorar sistemáticamente todas las sustituciones posibles en residuos clave.
- Display y técnicas sin células: métodos como phage display, ribosome display, mRNA display o displays en membrana celular permiten acoplar gen-fenotipo y facilitar la selección.
- Microcompartimentación en gotículas: encapsular el genotipo y su producto en microgotas (in vitro compartmentalization, IVC) para ligar actividad enzimática y ADN y permitir cribados masivos.
Selección vs cribado
Es importante distinguir dos enfoques:
- Selección: solo sobreviven o se amplifican las variantes que cumplen un criterio (por ejemplo, crecimiento celular dependiente de la actividad enzimática). Es muy eficiente para bibliotecas grandes porque no requiere examinar cada variante individualmente.
- Cribado: cada variante se prueba individualmente en un ensayo para medir su actividad, afinidad o estabilidad. Permite cuantificar propiedades y elegir las mejores, pero requiere técnicas de alto rendimiento si la biblioteca es grande.
Ejemplos de mejoras obtenidas
Mediante ED se han logrado mejoras prácticas como:
- Mayor actividad catalítica o mayor rendimiento en rutas sintéticas.
- Mejor estabilidad térmica o resistencia a disolventes y pH extremos.
- Aumento de la especificidad o selectividad quiral en síntesis de fármacos.
- Enzimas tolerantes a condiciones industriales (detergentes, procesos a alta temperatura, etc.).
Estos avances han tenido impacto industrial y académico; en 2018 la Nobel de Química reconoció a Frances H. Arnold por sus aportes pioneros a la evolución dirigida de enzimas.
Combinación con diseño racional y aprendizaje automático
La ED no es excluyente con el diseño racional. Hoy en día, los enfoques más efectivos suelen combinar:
- Diseño computacional para proponer mutaciones plausibles basadas en estructuras y modelos.
- Cribado experimental para validar y refinar candidatos.
- Aprendizaje automático y análisis de secuencias/actividad para predecir regiones prometedoras y reducir el tamaño de las bibliotecas necesarias.
Limitaciones y consideraciones prácticas
Entre los desafíos y límites de la ED se incluyen:
- Necesidad de un ensayo robusto que correlacione bien con la función deseada —un ensayo inadecuado puede seleccionar variantes no útiles en la aplicación final.
- Dependencia del tamaño y calidad de la biblioteca: aunque in vitro permite bibliotecas enormes, los ensayos deben poder explorar esa diversidad.
- Posibles costos y tiempo cuando se requieren múltiples rondas y cribados de alto rendimiento.
- Riesgos de que mejoras en condiciones de laboratorio no se traduzcan directamente en rendimiento en aplicaciones reales (problema de traslación).
Aspectos de bioseguridad y ética
Como toda tecnología genética, la ED requiere prácticas de bioseguridad, evaluación de posibles riesgos ambientales y cumplimiento normativo. En particular hay que considerar la contención apropiada de organismos modificados y el análisis de posibles efectos no intencionados antes de aplicarlos fuera del laboratorio.
Tendencias y futuro
Las direcciones actuales incluyen la integración más estrecha entre modelado computacional y cribados experimentales, la automatización de ciclos de evolución (biología sintética automatizada), el uso de microfluidos para cribados ultrarrápidos y la aplicación de métodos de IA para predecir secuencias funcionales. Esto abre la posibilidad de acelerar el descubrimiento de enzimas para nuevas reacciones químicas, terapias personalizadas y soluciones sostenibles en industria.
En resumen, la evolución dirigida es una herramienta poderosa que, mediante la generación de diversidad genética y la selección iterativa, permite diseñar proteínas y enzimas con propiedades adaptadas a necesidades concretas, combinando técnicas experimentales e informáticas para optimizar su aplicación.

Garantizar la herencia
Cuando se han aislado las proteínas funcionales, es necesario que sus genes también lo sean, por lo que se requiere un vínculo genotipo-fenotipo.
Puede ser covalente, cuando el gen del ARNm se une a la proteína al final de la traducción mediante puromicina.
Alternativamente, la proteína y su gen pueden mantenerse juntos, o en gotas de emulsión. Las secuencias genéticas aisladas se multiplican entonces por PCR o por bacterias huésped transformadas. La mejor secuencia, o un conjunto de secuencias, puede utilizarse como plantilla para la siguiente ronda de mutagénesis. Los ciclos repetidos de diversificación-selección-amplificación hacen que las variaciones enzimáticas se adapten al proceso de selección.

Premio concedido
La ingeniera estadounidense Frances Arnold ha ganado el Premio de Tecnología del Milenio por ser pionera en la evolución dirigida.
Preguntas y respuestas
P: ¿Qué es la evolución dirigida?
R: La evolución dirigida (ED) es un método utilizado para producir enzimas con fines industriales o médicos. Es una forma de ingeniería de proteínas que imita la selección natural.
P: ¿Cómo funciona la evolución dirigida?
R: La evolución dirigida funciona sometiendo un gen a rondas repetidas de mutación, creando una biblioteca de variantes. La selección aísla entonces los genes con la función deseada, que se utilizan como plantillas para la siguiente ronda.
P: ¿Dónde puede realizarse la evolución dirigida?
R: La evolución dirigida puede hacerse in vivo (en células vivas de bacterias o levaduras), o in vitro (libre en solución o microgotas).
P: ¿Cuáles son las ventajas de hacer evolución dirigida in vivo?
R: Hacer evolución dirigida in vivo tiene la ventaja de seleccionar las propiedades en un entorno celular, lo que es útil cuando la proteína o el ARN evolucionados se van a utilizar en organismos vivos.
P: ¿Qué ventajas tiene hacer evolución dirigida in vitro?
R: Hacer evolución dirigida in vitro tiene la ventaja de permitir más condiciones (por ejemplo, temperatura, disolventes) y puede expresar proteínas que serían tóxicas para las células. Además, puede generar bibliotecas mucho mayores porque no es necesario insertar el ADN en las células.
P: ¿Qué limita lo que puede hacerse durante un experimento in vitro?
R: El límite de tamaño de lo que se puede hacer durante un experimento in vitro suele estar determinado por la cantidad de ADN que es necesario insertar en las células.
Artículos relacionados
Autor
AlegsaOnline.com Evolución dirigida: ingeniería de proteínas y diseño de enzimas Leandro Alegsa
URL: https://es.alegsaonline.com/art/27599
Fuentes
- ncbi.nlm.nih.gov : Stephen Lutz 2010. Beyond directed evolution - semi-rational protein engineering and design. Curr Opin Biotechnol. 21(6): 734–743.
- doi.org : 10.1016/s0065-3233(01)55003-2
- pubmed.ncbi.nlm.nih.gov : 11050933
- doi.org : 10.1016/j.sbi.2011.05.003
- pubmed.ncbi.nlm.nih.gov : 21684150
- doi.org : 10.1016/j.cbpa.2014.09.040
- pubmed.ncbi.nlm.nih.gov : 25461718
- doi.org : 10.1016/j.sbi.2005.07.006
- pubmed.ncbi.nlm.nih.gov : 16043338
- doi.org : 10.1016/j.jim.2004.04.008
- pubmed.ncbi.nlm.nih.gov : 15261571
- doi.org : 10.1038/nbt1066
- pubmed.ncbi.nlm.nih.gov : 15696158
- doi.org : 10.1039/b907578j
- pubmed.ncbi.nlm.nih.gov : 20023716