Microarquitectura: diseño interno y organización de procesadores
Descripción técnica de la microarquitectura: qué es, sus componentes, evolución histórica, diferencias con la ISA y su impacto en rendimiento, consumo y seguridad de los procesadores.
Visión general
En ingeniería informática, la microarquitectura describe la estructura interna y la lógica de implementación de un ordenador o de una unidad central de procesamiento. Es la especificación de los circuitos eléctricos y los bloques funcionales que hacen posible ejecutar instrucciones definidas por una arquitectura del conjunto de instrucciones. La microarquitectura determina cómo el hardware traduce y organiza las operaciones abstractas en actividades eléctricas concretas.
Galería de imágenes
1 Imagen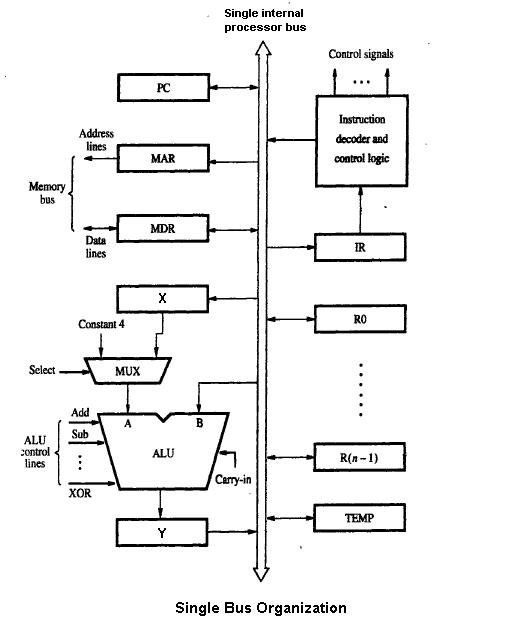
Componentes clave
Una microarquitectura típica integra varios subsistemas que cooperan para ejecutar código cliente y de sistema. Entre los elementos esenciales figuran:
- Unidad de control: coordina el flujo de datos y las señales de control.
- Registros y bancos de registros: almacenan valores de trabajo de baja latencia.
- ALU y unidades de punto flotante: realizan cálculos aritméticos y lógicos.
- Cachés y jerarquía de memoria: reducen la latencia de acceso a los datos.
- Canales de ejecución: pipelines, ejecución superescalar, unidades en paralelo y predicción de saltos.
- Sistemas especiales: coprocesadores, aceleradores y procesadores de señales digitales cuando aplican.
Estrategias de diseño y trade-offs
El diseño microarquitectónico equilibra rendimiento, consumo de energía, coste y complejidad. Algunas decisiones frecuentes son si usar microcódigo o lógica fija, implementar ejecución fuera de orden, agrupar instrucciones en pipelines largos o cortos, añadir predicción de bifurcación o aumentar ancho de banda con paralelismo SIMD. Cada elección afecta la latencia, el rendimiento sostenido, la compatibilidad binaria y la dificultad de verificación.
Evolución histórica
La microarquitectura ha evolucionado desde procesadores simples de ciclo único hacia diseños con canalización, cachés jerárquicos y ejecución fuera de orden. Distinciones históricas como RISC y CISC se han ido difuminando en la práctica: muchas implementaciones modernas combinan técnicas de ambos enfoques. En el discurso académico se emplea a menudo el término organización de los ordenadores, mientras que la industria prefiere "microarquitectura" para referirse a decisiones concretas de implementación.
Usos, impacto y consideraciones prácticas
La microarquitectura determina aspectos prácticos relevantes: rendimiento en aplicaciones reales, consumo energético en dispositivos móviles, coste por área de silicio y vulnerabilidades de seguridad relacionadas con optimizaciones (por ejemplo, las que involucran ejecución especulativa). Diferentes microarquitecturas pueden ejecutar el mismo conjunto de instrucciones con rendimientos y perfiles de consumo muy distintos, lo que influye en la elección del procesador para servidores, ordenadores personales, sistemas embebidos y teléfonos.
Diferencias importantes y compatibilidad
Es clave distinguir entre la microarquitectura y la arquitectura del conjunto de instrucciones: la ISA define el contrato visible por software, mientras que la microarquitectura describe cómo ese contrato se implementa en el nivel de hardware. La arquitectura informática engloba ambos aspectos. Un mismo ISA puede tener múltiples microarquitecturas, lo que permite innovar sin romper la compatibilidad binaria.
Para profundizar, consulte recursos técnicos sobre diseño de procesadores, optimización de compiladores y análisis de rendimiento en fuentes especializadas. En términos prácticos, la microarquitectura es la ingeniería que hace tangibles las abstracciones de la arquitectura y convierte instrucciones en señales eléctricas dentro del chip.
Origen del término
Los ordenadores utilizan la microprogramación de la lógica de control desde la década de 1950. La CPU descodifica las instrucciones y envía las señales por los caminos adecuados mediante interruptores de transistores. Los bits de las palabras del microprograma controlan el procesador a nivel de señales eléctricas.
El término: microarquitectura se utilizó para describir las unidades que eran controladas por las palabras del microprograma, en contraste con el término "arquitectura" que era visible y estaba documentada para los programadores. Mientras que la arquitectura normalmente tenía que ser compatible entre generaciones de hardware, la microarquitectura subyacente podía cambiarse fácilmente.
Relación con la arquitectura del conjunto de instrucciones
La microarquitectura está relacionada con la arquitectura del conjunto de instrucciones, pero no es lo mismo. La arquitectura del conjunto de instrucciones se aproxima al modelo de programación de un procesador tal y como lo ve un programador de lenguaje ensamblador o un escritor de compiladores, que incluye el modelo de ejecución, los registros del procesador, los modos de dirección de la memoria, los formatos de dirección y datos, etc. La microarquitectura (u organización del ordenador) es principalmente una estructura de nivel inferior y, por tanto, maneja un gran número de detalles que quedan ocultos en el modelo de programación. Describe las partes internas del procesador y cómo funcionan juntas para implementar la especificación arquitectónica.
Los elementos microarquitectónicos pueden ser desde puertas lógicas simples, pasando por registros, tablas de búsqueda, multiplexores, contadores, etc., hasta ALU completas, FPU e incluso elementos más grandes. El nivel de los circuitos electrónicos puede, a su vez, subdividirse en detalles a nivel de transistores, como qué estructuras básicas de construcción de puertas se utilizan y qué tipos de implementación lógica (estática/dinámica, número de fases, etc.) se eligen, además del diseño lógico real utilizado para construirlos.
Algunos puntos importantes:
- Una única microarquitectura, especialmente si incluye microcódigo, puede utilizarse para implementar muchos conjuntos de instrucciones diferentes, mediante el cambio del almacén de control. Sin embargo, esto puede ser bastante complicado, incluso cuando se simplifica con microcódigo y/o estructuras de tabla en las ROM o PLA.
- Dos máquinas pueden tener la misma microarquitectura, y por tanto el mismo diagrama de bloques, pero implementaciones de hardware completamente diferentes. Esto gestiona tanto el nivel de los circuitos electrónicos como, aún más, el nivel físico de la fabricación (tanto de los circuitos integrados como de los componentes discretos).
- Las máquinas con diferentes microarquitecturas pueden tener la misma arquitectura de conjunto de instrucciones, por lo que ambas son capaces de ejecutar los mismos programas. Las nuevas microarquitecturas y/o soluciones de circuitos, junto con los avances en la fabricación de semiconductores, son las que permiten que las nuevas generaciones de procesadores alcancen un mayor rendimiento.
Descripciones simplificadas
Una descripción de alto nivel muy simplificada -común en la comercialización- puede mostrar sólo características bastante básicas, como los anchos de bus, junto con varios tipos de unidades de ejecución y otros grandes sistemas, como la predicción de bifurcaciones y las memorias caché, representados como simples bloques, quizás con algunos atributos o características importantes anotados. A veces también pueden incluirse algunos detalles relativos a la estructura de la tubería (como la obtención, descodificación, asignación, ejecución, escritura y devolución).
Aspectos de la microarquitectura
La ruta de datos en tuberías es el diseño de ruta de datos más utilizado en la microarquitectura actual. Esta técnica se utiliza en la mayoría de los microprocesadores, microcontroladores y DSP modernos. La arquitectura de canalización permite que varias instrucciones se superpongan en la ejecución, de forma muy parecida a una línea de montaje. El pipeline incluye varias etapas diferentes que son fundamentales en los diseños de microarquitectura. Algunas de estas etapas incluyen la obtención de instrucciones, la decodificación de instrucciones, la ejecución y la escritura de retorno. Algunas arquitecturas incluyen otras etapas, como el acceso a la memoria. El diseño de los pipelines es una de las tareas centrales de la microarquitectura.
Las unidades de ejecución también son esenciales para la microarquitectura. Las unidades de ejecución incluyen las unidades aritméticas lógicas (ALU), las unidades de coma flotante (FPU), las unidades de carga/almacenamiento y la predicción de ramas. Estas unidades realizan las operaciones o cálculos del procesador. La elección del número de unidades de ejecución, su latencia y su rendimiento son importantes tareas de diseño microarquitectónico. El tamaño, la latencia, el rendimiento y la conectividad de las memorias dentro del sistema también son decisiones microarquitectónicas.
Las decisiones de diseño a nivel de sistema, como la de incluir o no periféricos, como los controladores de memoria, pueden considerarse parte del proceso de diseño microarquitectónico. Esto incluye las decisiones sobre el nivel de rendimiento y la conectividad de estos periféricos.
A diferencia del diseño arquitectónico, en el que un nivel de rendimiento específico es el objetivo principal, el diseño microarquitectónico presta más atención a otras limitaciones. Hay que prestar atención a cuestiones como:
- Superficie/coste del chip.
- Consumo de energía.
- Complejidad lógica.
- Facilidad de conexión.
- Fabricabilidad.
- Facilidad de depuración.
- Probabilidad.
Conceptos de microarquitectura
En general, todas las CPU, los microprocesadores de un solo chip o las implementaciones de varios chips, ejecutan programas realizando los siguientes pasos:
- Lea una instrucción y descodifíquela.
- Encuentre cualquier dato asociado que sea necesario para procesar la instrucción.
- Procese la instrucción.
- Escriba los resultados.
Lo que complica esta serie de pasos de apariencia sencilla es el hecho de que la jerarquía de la memoria, que incluye la caché, la memoria principal y el almacenamiento no volátil como los discos duros, (donde están las instrucciones y los datos del programa) siempre ha sido más lenta que el propio procesador. El paso (2) a menudo introduce un retraso (en términos de la CPU, a menudo llamado "atasco") mientras los datos llegan por el bus del ordenador. Se ha dedicado una gran cantidad de investigación a los diseños que evitan estos retrasos en la medida de lo posible. A lo largo de los años, un objetivo central del diseño era ejecutar más instrucciones en paralelo, aumentando así la velocidad efectiva de ejecución de un programa. Estos esfuerzos introdujeron complicadas estructuras lógicas y de circuitos. En el pasado, estas técnicas sólo podían implementarse en costosos mainframes o superordenadores debido a la cantidad de circuitos necesarios para estas técnicas. A medida que progresaba la fabricación de semiconductores, cada vez más de estas técnicas podían implementarse en un solo chip semiconductor.
Lo que sigue es un estudio de las técnicas de microarquitectura que son comunes en las CPUs modernas.
Elección del conjunto de instrucciones
La elección de la arquitectura del conjunto de instrucciones que se va a utilizar afecta en gran medida a la complejidad de la implementación de dispositivos de alto rendimiento. A lo largo de los años, los diseñadores de ordenadores han hecho todo lo posible para simplificar los conjuntos de instrucciones, con el fin de permitir implementaciones de mayor rendimiento, ahorrando a los diseñadores esfuerzo y tiempo para las características que mejoran el rendimiento en lugar de malgastarlos en la complejidad del conjunto de instrucciones.
El diseño del conjunto de instrucciones ha progresado desde los tipos CISC, RISC, VLIW y EPIC. Las arquitecturas que se ocupan del paralelismo de datos incluyen SIMD y Vectores.
Canalización de instrucciones
Una de las primeras, y más poderosas, técnicas para mejorar el rendimiento es el uso del pipeline de instrucciones. Los primeros diseños de procesadores realizaban todos los pasos anteriores en una instrucción antes de pasar a la siguiente. Grandes partes de los circuitos del procesador quedaban ociosas en cualquier paso; por ejemplo, los circuitos de decodificación de instrucciones estarían ociosos durante la ejecución y así sucesivamente.
Las tuberías mejoran el rendimiento al permitir que un número de instrucciones se abran paso en el procesador al mismo tiempo. En el mismo ejemplo básico, el procesador empezaría a descodificar (paso 1) una nueva instrucción mientras la última está esperando resultados. Esto permitiría que hasta cuatro instrucciones estuvieran "en vuelo" al mismo tiempo, haciendo que el procesador parezca cuatro veces más rápido. Aunque cualquier instrucción tarda el mismo tiempo en completarse (sigue habiendo cuatro pasos), la CPU en su conjunto "retira" las instrucciones mucho más rápido y puede funcionar a una velocidad de reloj mucho mayor.
Caché
Las mejoras en la fabricación de chips permitieron colocar más circuitos en el mismo chip, y los diseñadores empezaron a buscar formas de utilizarlos. Una de las formas más comunes fue añadir una cantidad cada vez mayor de memoria caché en el chip. La caché es una memoria muy rápida, una memoria a la que se puede acceder en pocos ciclos en comparación con lo que se necesita para hablar con la memoria principal. La CPU incluye un controlador de caché que automatiza la lectura y la escritura desde la caché, si los datos ya están en la caché simplemente "aparecen", mientras que si no lo están el procesador se "paraliza" mientras el controlador de caché los lee.
Los diseños RISC empezaron a añadir caché a mediados y finales de los años 80, a menudo con un total de 4 KB. Este número creció con el tiempo, y las CPUs típicas tienen ahora unos 512 KB, mientras que las más potentes vienen con 1 o 2 o incluso 4, 6, 8 o 12 MB, organizados en múltiples niveles de una jerarquía de memoria. En general, más caché significa más velocidad.
Las memorias caché y los pipelines encajaban perfectamente entre sí. Anteriormente, no tenía mucho sentido construir una tubería que pudiera ejecutarse más rápido que la latencia de acceso de la memoria caché fuera del chip. En cambio, utilizar la memoria caché en el chip significaba que una tubería podía funcionar a la velocidad de la latencia de acceso a la caché, un tiempo mucho menor. Esto permitió que las frecuencias de funcionamiento de los procesadores aumentaran a un ritmo mucho más rápido que el de la memoria fuera del chip.
Predicción de ramas y ejecución especulativa
Las paradas de la tubería y los vaciados debidos a las bifurcaciones son las dos cosas principales que impiden lograr un mayor rendimiento mediante el paralelismo a nivel de instrucción. Desde el momento en que el decodificador de instrucciones del procesador ha descubierto que ha encontrado una instrucción de bifurcación condicional hasta el momento en que se puede leer el valor del registro de salto decisivo, la tubería puede estar estancada durante varios ciclos. Por término medio, una de cada cinco instrucciones ejecutadas es una bifurcación, por lo que se trata de una cantidad elevada de estancamiento. Si se toma la bifurcación, es aún peor, ya que entonces todas las instrucciones subsiguientes que estaban en la tubería deben ser vaciadas.
Técnicas como la predicción de bifurcaciones y la ejecución especulativa se utilizan para reducir estas penalizaciones de las bifurcaciones. La predicción de bifurcación consiste en que el hardware hace conjeturas sobre si se tomará una determinada bifurcación. La conjetura permite al hardware prefijar las instrucciones sin esperar a la lectura del registro. La ejecución especulativa es una mejora adicional en la que el código a lo largo de la ruta predicha se ejecuta antes de que se sepa si la rama debe tomarse o no.
Ejecución fuera de orden
La adición de cachés reduce la frecuencia o la duración de las paradas debidas a la espera de los datos que se obtienen de la jerarquía de la memoria principal, pero no elimina por completo estas paradas. En los primeros diseños, una pérdida de caché obligaba al controlador de caché a detener el procesador y esperar. Por supuesto, puede haber alguna otra instrucción en el programa cuyos datos estén disponibles en la caché en ese momento. La ejecución fuera de orden permite procesar esa instrucción lista mientras una instrucción más antigua espera en la caché, y luego reordena los resultados para que parezca que todo ha ocurrido en el orden programado.
Superescalar
Incluso con toda la complejidad añadida y las puertas necesarias para soportar los conceptos expuestos, las mejoras en la fabricación de semiconductores pronto permitieron utilizar aún más puertas lógicas.
En el esquema anterior, el procesador procesa partes de una sola instrucción a la vez. Los programas informáticos podrían ejecutarse más rápidamente si se procesaran múltiples instrucciones simultáneamente. Esto es lo que consiguen los procesadores superescalares, al replicar unidades funcionales como las ALU. La replicación de las unidades funcionales sólo fue posible cuando el área del circuito integrado (a veces llamado "die") de un procesador de una sola instrucción ya no alcanzaba los límites de lo que podía fabricarse de forma fiable. A finales de la década de 1980, los diseños superescalares comenzaron a entrar en el mercado.
En los diseños modernos es habitual encontrar dos unidades de carga, una de almacenamiento (muchas instrucciones no tienen resultados que almacenar), dos o más unidades matemáticas de enteros, dos o más unidades de coma flotante y, a menudo, una unidad SIMD de algún tipo. La lógica de emisión de instrucciones crece en complejidad al leer una enorme lista de instrucciones de la memoria y entregarlas a las diferentes unidades de ejecución que están ociosas en ese momento. Los resultados se recogen entonces y se reordenan al final.
Cambio de nombre del registro
El renombramiento de registros se refiere a una técnica utilizada para evitar la ejecución innecesaria en serie de las instrucciones del programa debido a la reutilización de los mismos registros por parte de dichas instrucciones. Supongamos que tenemos dos grupos de instrucciones que utilizarán el mismo registro, un conjunto de instrucciones se ejecuta primero para dejar el registro al otro conjunto, pero si el otro conjunto se asigna a un registro similar diferente, ambos conjuntos de instrucciones pueden ejecutarse en paralelo.
Multiprocesamiento y multihilo
Debido a la creciente brecha entre las frecuencias de funcionamiento de la CPU y los tiempos de acceso a la DRAM, ninguna de las técnicas que mejoran el paralelismo a nivel de instrucciones (ILP) dentro de un programa podía superar los largos estancamientos (retrasos) que se producían cuando había que obtener datos de la memoria principal. Además, los grandes recuentos de transistores y las altas frecuencias de funcionamiento necesarias para las técnicas de ILP más avanzadas requerían niveles de disipación de energía que ya no se podían refrigerar de forma barata. Por estas razones, las nuevas generaciones de ordenadores han empezado a utilizar niveles más altos de paralelismo que existen fuera de un solo programa o hilo de programa.
Esta tendencia se conoce a veces como "computación de rendimiento". Esta idea se originó en el mercado de los mainframes, donde el procesamiento de transacciones en línea ponía el acento no sólo en la velocidad de ejecución de una transacción, sino en la capacidad de gestionar un gran número de transacciones al mismo tiempo. Con las aplicaciones basadas en transacciones, como el enrutamiento de la red y el servicio de sitios web, que han aumentado mucho en la última década, la industria informática ha vuelto a hacer hincapié en las cuestiones de capacidad y rendimiento.
Una técnica de cómo se consigue este paralelismo es a través de los sistemas de multiprocesamiento, sistemas informáticos con múltiples CPU. En el pasado esto estaba reservado a los mainframes de gama alta, pero ahora los servidores multiprocesadores a pequeña escala (2-8) se han convertido en algo habitual para el mercado de las pequeñas empresas. Para las grandes empresas, son comunes los multiprocesadores a gran escala (16-256). Incluso los ordenadores personales con múltiples CPUs han aparecido desde la década de 1990.
Los avances en la tecnología de los semiconductores redujeron el tamaño de los transistores; han aparecido las CPUs multinúcleo, en las que se implementan múltiples CPUs en el mismo chip de silicio. Inicialmente se utilizaban en los chips destinados a los mercados integrados, donde las CPU más sencillas y pequeñas permitían que las múltiples instancias cupieran en una sola pieza de silicio. En 2005, la tecnología de los semiconductores permitía fabricar en volumen chips CMP de CPUs duales de gama alta para ordenadores de sobremesa. Algunos diseños, como el UltraSPARC T1, utilizaban diseños más sencillos (escalares, en orden) para que cupieran más procesadores en una pieza de silicio.
Recientemente, otra técnica que se ha hecho más popular es el multihilo. En el multithreading, cuando el procesador tiene que obtener datos de la memoria lenta del sistema, en lugar de quedarse parado hasta que lleguen los datos, el procesador cambia a otro programa o hilo de programa que esté listo para ejecutarse. Aunque esto no acelera un programa/hilo concreto, aumenta el rendimiento general del sistema al reducir el tiempo que la CPU está inactiva.
Conceptualmente, el multihilo es equivalente a un cambio de contexto a nivel del sistema operativo. La diferencia es que una CPU multihilo puede realizar un cambio de hilo en un ciclo de CPU en lugar de los cientos o miles de ciclos de CPU que normalmente requiere un cambio de contexto. Esto se consigue replicando el hardware de estado (como el archivo de registro y el contador de programa) para cada hilo activo.
Otra mejora es el multihilo simultáneo. Esta técnica permite a las CPUs superescalares ejecutar instrucciones de diferentes programas/hilos simultáneamente en el mismo ciclo.
Páginas relacionadas
- Microprocesador
- Microcontrolador
- Procesador multinúcleo
- Procesador digital de señales
- Diseño de la CPU
- Ruta de datos
- paralelismo a nivel de instrucción (ILP)
Preguntas y respuestas
P: ¿Qué es la microarquitectura?
R: La microarquitectura es una descripción de los circuitos eléctricos de un ordenador, de una unidad central de procesamiento o de un procesador de señales digitales que es suficiente para describir completamente el funcionamiento del hardware.
P: ¿Cómo se refieren los estudiosos a este concepto?
R: Los académicos utilizan el término "organización del ordenador" cuando se refieren a la microarquitectura.
P: ¿Cómo se refiere la gente de la industria informática a este concepto?
R: La gente de la industria informática suele decir "microarquitectura" cuando se refiere a este concepto.
P: ¿Qué dos campos componen la arquitectura de los ordenadores?
R: La microarquitectura y la arquitectura del conjunto de instrucciones (ISA) constituyen conjuntamente el campo de la arquitectura informática.
P: ¿Qué significa ISA?
R: ISA son las siglas de Instruction Set Architecture (arquitectura del conjunto de instrucciones).
P: ¿Qué significa µarch? R: µArch significa microarquitectura.
Artículos relacionados
Autor
AlegsaOnline.com Microarquitectura: diseño interno y organización de procesadores Leandro Alegsa
URL: https://es.alegsaonline.com/art/64586
Fuentes
- computer.org : IEEE Computer Society
- extremetech.com : PC Processor Microarchitecture