CPU superescalar: ¿qué es y cómo funciona?
CPU superescalar: qué es y cómo funciona — descubre cómo ejecutan múltiples instrucciones por ciclo, el paralelismo a nivel de instrucción, unidades funcionales y despacho para maximizar rendimiento.
Un diseño de CPU superescalar realiza una forma de computación paralela denominada paralelismo a nivel de instrucción dentro de una única CPU, lo que permite hacer más trabajo a la misma velocidad de reloj. En la práctica, esto significa que la CPU puede ejecutar más de una instrucción durante un mismo ciclo de reloj despachando varias instrucciones en paralelo a distintas unidades funcionales duplicadas. Cada unidad funcional es un recurso de ejecución dentro del núcleo —por ejemplo, una unidad aritmética lógica (ALU), una unidad de coma flotante (FPU), un multiplicador o una unidad dedicada a operaciones de bits— y varias de ellas permiten realizar varias operaciones independientes al mismo tiempo.
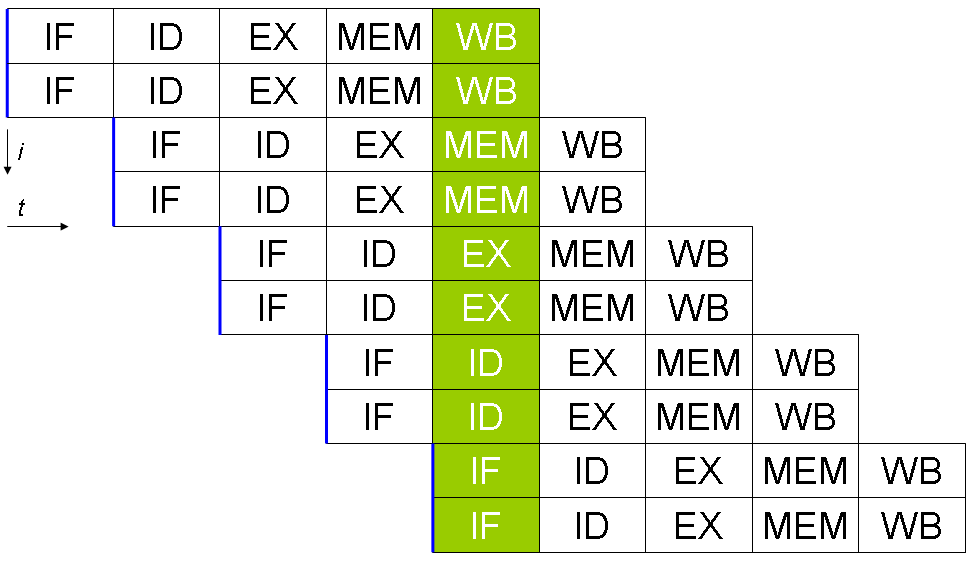
La mayoría de las CPUs superescalares también están canalizadas. Canalización y superescalaridad son conceptos distintos: la canalización divide la ejecución de cada instrucción en etapas (fetch, decode, execute, etc.) para aumentar el rendimiento por reloj, mientras que la superescalaridad aumenta el número de instrucciones que pueden estar en ejecución simultáneamente. Es posible, en teoría, tener una CPU superescalar no canalizada o una CPU canalizada que no sea superescalar, aunque en la práctica modernas implementaciones combinan ambas técnicas.
Galería de imágenes
2 Imágenes
Características clave del diseño superescalar
La técnica superescalar se apoya en varias características del núcleo de la CPU para encontrar y ejecutar instrucciones en paralelo:
- Las instrucciones provienen de una secuencia ordenada (el flujo del programa).
- El hardware puede detectar dependencias de datos y control entre instrucciones (qué instrucciones dependen del resultado de otras).
- La CPU puede leer y procesar múltiples instrucciones por ciclo de reloj desde la etapa de búsqueda/decodificación.
Además, para mantener ocupadas las unidades funcionales y explotar el paralelismo disponible, las CPUs superescalares modernas implementan microarquitecturas con varios bloques de soporte, como:
- Prefetch y fetch anchos: leer múltiples instrucciones por ciclo.
- Decodificadores múltiples: decodificar varias instrucciones simultáneamente.
- Despacho (issue) avanzado: decidir qué instrucciones enviar a qué unidades.
- Ejecutores múltiples: varias ALU, FPU y unidades SIMD.
- Reordenación y commit: mecanismos para ejecutar fuera de orden y luego confirmar resultados en orden (reorder buffer).
Cómo funciona el flujo de instrucciones
En una CPU superescalar, el proceso típico incluye varias etapas cooperantes:
- Fetch: se recuperan varias instrucciones de memoria/cache.
- Decode: se traducen a microoperaciones (a veces) y se identifican recursos necesarios.
- Detectar dependencias: el hardware comprueba dependencias de datos (RAW, WAR, WAW) y dependencias de control (saltos).
- Despacho/Issue: el despachador de instrucciones decide qué instrucciones pueden ejecutarse en paralelo y las envía a las unidades funcionales libres.
- Ejecutar: las unidades funcionales realizan las operaciones.
- Commit/Retirar: los resultados se confirman en el orden correcto para asegurar el modelo de programación observable.
Para maximizar el paralelismo y resolver dependencias, algunas CPUs ejecutan instrucciones fuera de orden (out-of-order) y usan técnicas como renombrado de registros para evitar dependencias artificiales entre instrucciones sucesivas. Algoritmos históricos y modernos como Tomasulo, reservas de estaciones y reorder buffer son ejemplos de estructuras que permiten ejecutar y completar instrucciones de forma segura y eficiente.
Problemas y limitaciones
Una CPU superescalar no garantiza siempre un mayor rendimiento; está limitada por varios factores:
- Dependencias de datos: si muchas instrucciones dependen unas de otras (cadenas de dependencias), no se pueden ejecutar en paralelo.
- Dependencias de control: los saltos y las ramas obligan al procesador a predecir el flujo de control; la precisión de la predicción de ramas es crítica para mantener el despacho.
- Contención de recursos (hazards estructurales): si no hay suficientes unidades funcionales o puertos de acceso a la memoria, las instrucciones deben esperar.
- Complejidad y consumo: hardware más complejo para detección de dependencias, renombrado de registros y buffers grandes aumenta consumo energético y área del chip.
Superscalar vs otros modelos
Comparado con otros enfoques:
- Un procesador escalar ejecuta típicamente una instrucción por ciclo (o pocas) y no tiene múltiples vías de ejecución paralela internas.
- Un procesador vectorial o basado en SIMD aplica la misma operación a muchos datos a la vez; la superescalaridad procesa múltiples instrucciones (cada una sobre un dato o vector) en paralelo.
- VLIW (Very Long Instruction Word) delega en el compilador la tarea de agrupar instrucciones independientes en palabras largas para ejecución paralela, mientras que las arquitecturas superescalares hacen esa selección dinámicamente en hardware.
Implementaciones y ejemplos prácticos
Hoy en día, prácticamente todas las CPU de propósito general incluyen algún grado de superescalaridad. Las implementaciones varían en anchura (issue width): hay diseños 2-way, 4-way, 6-way o más, que indican cuántas instrucciones pueden despacharse idealmente por ciclo. Un núcleo típico moderno puede integrar varias ALU, una o más FPU y unidades SIMD para operaciones vectoriales; por ejemplo, es habitual ver configuraciones como 4 ALU, 2 FPU y unidades SIMD adicionales, aunque la combinación exacta depende del microdiseño.
Arquitecturas comerciales como las familias x86 modernas y muchos núcleos ARM usan superescalaridad (a menudo junto con ejecución fuera de orden y predicción de ramas sofisticada) para aumentar el rendimiento por núcleo. Sin embargo, el paralelismo real que consigue el procesador depende de la naturaleza del código ejecutado y de la habilidad del hardware para encontrar instrucciones independientes.
Resumen
La superescalaridad es una técnica microarquitectónica que permite a una CPU ejecutar múltiples instrucciones en paralelo dentro de un mismo núcleo, aumentando el rendimiento sin subir la velocidad de reloj. Requiere mecanismos para detectar dependencias, leer y decodificar múltiples instrucciones por ciclo, y distribuirlas eficientemente a unidades funcionales duplicadas. Sus beneficios son notables en código con suficiente paralelismo a nivel de instrucción, mientras que su complejidad y consumo limitan hasta dónde conviene escalar este enfoque.
En una CPU superescalar, un despachador de instrucciones lee las instrucciones de la memoria y decide cuáles pueden ejecutarse en paralelo, despachándolas en las múltiples unidades funcionales duplicadas disponibles dentro de la CPU. El diseño se centra en mejorar la precisión del despachador y en mantener ocupadas las unidades funcionales para maximizar el rendimiento; si el despachador no puede mantener todas las unidades ocupadas, el rendimiento será menor.


Limitaciones
La mejora del rendimiento en el diseño de CPUs superescalares está limitada por dos cosas:
- El nivel de paralelismo incorporado en la lista de instrucciones
- La complejidad y el coste de tiempo del despachador y la comprobación de la dependencia de los datos.
Incluso con una comprobación de dependencias infinitamente rápida dentro de una CPU superescalar normal, si la propia lista de instrucciones tiene muchas dependencias, esto también limitaría la posible mejora del rendimiento, por lo que la cantidad de paralelismo incorporado en el código es otra limitación.
Por muy rápida que sea la velocidad del despachador, existe un límite práctico en cuanto al número de instrucciones que pueden despacharse simultáneamente. Aunque los avances en el hardware permitirán tener más unidades funcionales (por ejemplo, ALU) por núcleo de CPU, el problema de comprobar las dependencias de las instrucciones aumenta hasta el punto de que el límite de despacho superescalar alcanzable es algo pequeño. -- Es probable que sea del orden de cinco a seis instrucciones despachadas simultáneamente.
Alternativas
- El multithreading simultáneo, a menudo abreviado como SMT, es una técnica para mejorar la velocidad global de las CPU superescalares. El SMT permite que varios hilos de ejecución independientes utilicen mejor los recursos disponibles dentro de un procesador superescalar moderno.
- Procesadores multinúcleo: los procesadores superescalares se diferencian de los procesadores multinúcleo en que las múltiples unidades funcionales redundantes no son procesadores completos. Un único procesador superescalar está compuesto por unidades funcionales avanzadas como la ALU, el multiplicador de enteros, el cambiador de enteros, la unidad de coma flotante (FPU), etc. Puede haber varias versiones de cada unidad funcional para permitir la ejecución de muchas instrucciones en paralelo. Esto difiere de los procesadores multinúcleo que procesan simultáneamente instrucciones de múltiples hilos, un hilo por núcleo.
- Procesadores canalizados: los procesadores superescalares también se diferencian de una CPU canalizada, en la que las múltiples instrucciones pueden estar simultáneamente en varias etapas de ejecución.
Las distintas técnicas alternativas no se excluyen mutuamente: pueden combinarse (y a menudo se combinan) en un único procesador, por lo que es posible diseñar una CPU multinúcleo en la que cada núcleo es un procesador independiente con múltiples canalizaciones superescalares paralelas. Algunos procesadores multinúcleo también incluyen capacidad vectorial.
Páginas relacionadas
- Computación paralela
- Paralelismo a nivel de instrucción
- Multihilo simultáneo (SMT)
- Procesadores multinúcleo
Preguntas y respuestas
P: ¿Qué es la tecnología superescalar?
R: La tecnología superescalar es una forma de computación paralela básica que permite procesar más de una instrucción en cada ciclo de reloj utilizando varias unidades de ejecución al mismo tiempo.
P: ¿Cómo funciona la tecnología superescalar?
R: La tecnología superescalar implica que las instrucciones llegan al procesador en orden, buscando dependencias de datos mientras se ejecuta y cargando más de una instrucción en cada ciclo de reloj.
P: ¿Cuál es la diferencia entre los procesadores escalares y vectoriales?
R: En un procesador escalar, las instrucciones suelen trabajar con uno o dos elementos de datos a la vez, mientras que en un procesador vectorial, las instrucciones suelen trabajar con muchos elementos de datos a la vez. Un procesador superescalar es una mezcla de ambos, ya que cada instrucción procesa un elemento de datos pero se ejecuta más de una instrucción a la vez, por lo que el procesador maneja muchos elementos de datos a la vez.
P: ¿Qué papel desempeña un despachador de instrucciones preciso en un procesador superescalar?
R: Un despachador de instrucciones preciso es muy importante para un procesador superescalar, ya que garantiza que las unidades de ejecución estén siempre ocupadas con el trabajo que probablemente se necesitará. Si el despachador de instrucciones no es preciso, es posible que haya que desechar parte del trabajo, lo que haría que no fuera más rápido que un procesador superescalar.
P: ¿En qué año todas las CPU normales se convirtieron en superescalares?
R: Todas las CPU normales se convirtieron en superescalares en 2008.
P: ¿Cuántas ALU, FPU y unidades SIMD puede haber en una CPU normal?
R: En una CPU normal puede haber hasta 4 ALU, 2 FPU y 2 unidades SIMD.
Artículos relacionados
Autor
AlegsaOnline.com CPU superescalar: ¿qué es y cómo funciona? Leandro Alegsa
URL: https://es.alegsaonline.com/art/95080