Redes neuronales: definición, funcionamiento y aplicaciones en IA
Redes neuronales: qué son, cómo funcionan y sus aplicaciones en IA — aprendizaje profundo, visión, lenguaje y soluciones inteligentes para empresas.
Una red neuronal (también llamada RNA o red neuronal artificial) es una especie de software informático, inspirado en las neuronas biológicas. Los cerebros biológicos son capaces de resolver problemas difíciles, pero cada neurona sólo es responsable de resolver una parte muy pequeña del problema. Del mismo modo, una red neuronal está formada por células que trabajan juntas para producir un resultado deseado, aunque cada célula individual sólo es responsable de resolver una pequeña parte del problema. Este es un método para crear programas artificialmente inteligentes.
Las redes neuronales son un ejemplo de aprendizaje automático, en el que un programa puede cambiar a medida que aprende a resolver un problema. Una red neuronal puede ser entrenada y mejorada con cada ejemplo, pero cuanto más grande es la red neuronal, más ejemplos necesita para funcionar bien, necesitando a menudo millones o miles de millones de ejemplos en el caso del aprendizaje profundo.
Galería de imágenes
6 Imágenes




¿Cómo funcionan las redes neuronales?
En términos sencillos, una red neuronal está compuesta por capas de unidades llamadas neuronas artificiales o nodos. Cada neurona recibe entradas, las combina mediante pesos y sesgos, aplica una función de activación y produce una salida que se transmite a las neuronas de la siguiente capa. Los elementos clave del funcionamiento son:
- Entradas: los datos iniciales (imágenes, texto, señales, etc.).
- Pesos y sesgos: parámetros que la red ajusta durante el entrenamiento. Controlan la influencia de cada entrada.
- Funciones de activación: introducen no linealidad (por ejemplo, ReLU, sigmoide, tanh) permitiendo resolver problemas complejos.
- Capas: estructura típica: capa de entrada, una o varias capas ocultas y capa de salida.
- Salida: la predicción o decisión final (clasificación, regresión, generación de texto, etc.).
Entrenamiento: aprendizaje y ajuste de parámetros
El proceso de entrenamiento ajusta los pesos y sesgos para minimizar un función de pérdida que mide el error entre la salida de la red y la respuesta correcta. Los pasos básicos son:
- Propagación hacia delante: calcular la salida para un ejemplo de entrenamiento.
- Cálculo de la pérdida: evaluar cuánto se aleja la predicción del valor deseado.
- Retropropagación (backpropagation): calcular gradientes de la pérdida respecto a los parámetros.
- Optimización: actualizar pesos usando algoritmos como SGD, Adam, RMSprop, etc.
Existen diferentes paradigmas de aprendizaje: supervisado (con etiquetas), no supervisado (descubrir estructura en datos sin etiquetas) y por refuerzo (aprendizaje mediante recompensas). Además, se usan técnicas para evitar el sobreajuste (overfitting) y mejorar la generalización: regularización, dropout, aumento de datos, validación cruzada, etc.
Tipos y arquitecturas comunes
Las redes neuronales adoptan muchas formas según la tarea:
- Perceptrón y redes feedforward: fluyen de entrada a salida sin ciclos; son la base del aprendizaje supervisado.
- Redes convolucionales (CNN): diseñadas para procesar datos con estructura espacial (imágenes, vídeo); usan filtros que detectan patrones locales.
- Redes recurrentes (RNN) y variantes (LSTM, GRU): adecuadas para datos secuenciales como texto y señales temporales.
- Transformers: basados en mecanismos de atención; hoy dominan tareas de procesamiento de lenguaje natural y generación de secuencias.
- Autoencoders y redes generativas: para reducción de dimensionalidad, compresión y generación de datos (ej.: GANs, VAEs).
Aplicaciones prácticas
Las redes neuronales se emplean en numerosos campos, por ejemplo:
- Visión por computador: reconocimiento de objetos, segmentación, diagnóstico por imagen en medicina.
- Procesamiento del lenguaje natural (NLP): traducción automática, clasificación de texto, asistentes conversacionales y modelos de lenguaje.
- Reconocimiento de voz y síntesis: conversión voz-texto y generación de voz natural.
- Robótica y control: navegación autónoma, manipulación y aprendizaje de políticas.
- Finanzas y comercio: detección de fraude, predicción de mercados, análisis de clientes.
- Ciencias de la salud: descubrimiento de fármacos, modelos predictivos de enfermedades, análisis genómicos.
Ventajas y limitaciones
Las redes neuronales ofrecen:
- Gran capacidad: pueden aproximar funciones muy complejas y aprender representaciones útiles automáticamente.
- Flexibilidad: adaptables a multitud de tipos de datos y tareas.
Sin embargo, presentan retos:
- Necesidad de datos: las redes grandes requieren grandes volúmenes de datos etiquetados y cómputo intensivo.
- Interpretabilidad limitada: suelen ser cajas negras; explicar por qué toman una decisión puede ser difícil.
- Sesgos y seguridad: si los datos contienen sesgos, la red los aprende; además son vulnerables a ataques adversarios.
- Coste energético y ambiental: entrenar modelos muy grandes consume mucha energía y recursos.
Buenas prácticas y consideraciones
- Reunir y limpiar datos representativos para evitar sesgos.
- Usar conjuntos de validación y pruebas separadas para medir generalización.
- Aplicar regularización y técnicas de calibrado para reducir sobreajuste.
- Evaluar el impacto ético y social antes de desplegar modelos en entornos sensibles.
- Monitorizar el rendimiento en producción y actualizar el modelo según cambien los datos.
Perspectivas futuras
La investigación sigue avanzando en hacer las redes más eficientes, explicables y seguras. Áreas activas incluyen arquitecturas más compactas, aprendizaje con menos datos (few-shot y self-supervised), mejores métodos de interpretación y normas para un uso responsable de la IA.
En resumen, las redes neuronales son una herramienta fundamental del artificialmente inteligentes moderno: potentes y versátiles, pero requieren datos, recursos y consideraciones éticas para su uso efectivo y seguro.
Visión general
Una red neuronal modela una red de neuronas, como las del cerebro humano. Cada neurona realiza operaciones matemáticas sencillas: recibe datos de otras neuronas, los modifica y los envía a otras neuronas. Las neuronas se colocan en "capas": una neurona de una capa recibe datos de las neuronas de otras capas, los modifica y envía datos a las neuronas de otras capas. Una red neuronal está formada por una o varias capas.
La primera capa se llama "capa de entrada", recibe datos del mundo exterior (por ejemplo: una imagen o un texto). La última capa se llama "capa de salida". Los datos de las neuronas de la capa de salida se leen y se utilizan como salida de la red. Las otras capas se denominan "capas ocultas".
En una red simple "feed-forward", los datos que manejan las neuronas son números.  Cada neurona hace una suma ponderada del valor de las neuronas de la capa anterior ( X_{i}} en la ecuación siguiente). A continuación, le añade un valor constante (llamado "sesgo"). Por último, aplica una función matemática a este valor, denominada "función de activación". La función de activación suele ser una función que devuelve un valor entre 0 y 1, como tanh.
Cada neurona hace una suma ponderada del valor de las neuronas de la capa anterior ( X_{i}} en la ecuación siguiente). A continuación, le añade un valor constante (llamado "sesgo"). Por último, aplica una función matemática a este valor, denominada "función de activación". La función de activación suele ser una función que devuelve un valor entre 0 y 1, como tanh.  El resultado de la función de activación ( Y_{j}} en la ecuación siguiente) se envía entonces a las neuronas de la capa siguiente.
El resultado de la función de activación ( Y_{j}} en la ecuación siguiente) se envía entonces a las neuronas de la capa siguiente.

Se define una función de pérdida para la red. La función de pérdida trata de estimar lo bien que lo hace la red neuronal en su tarea asignada. Finalmente, se aplica una técnica de optimización para minimizar la salida de la función de coste cambiando los pesos y los sesgos de la red. Este proceso se llama entrenamiento. El entrenamiento se realiza un pequeño paso a la vez. Después de miles de pasos, la red suele ser capaz de realizar su tarea asignada bastante bien.
Ejemplo
Considere un programa que comprueba si una persona está viva. Comprueba dos cosas: el pulso y la respiración. Si una persona tiene pulso o respira, el programa emitirá "vivo", de lo contrario, emitirá "muerto". En un programa que no aprende con el tiempo, esto se escribiría como
function isAlive(pulse, breathing) { if(pulse || breathing) { return true; } else { return false; } }
Una red neuronal muy sencilla, formada por una sola neurona que resuelve el mismo problema, tendrá el siguiente aspecto:
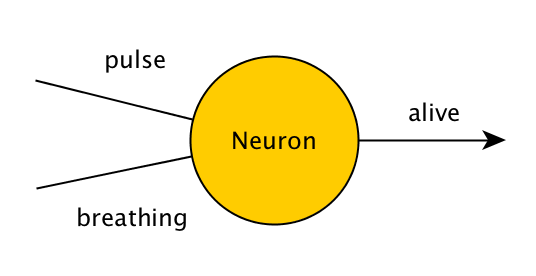
Los valores de pulso, respiración y vivo serán o bien 0 o bien 1, lo que representa falso y verdadero. Por lo tanto, si a esta neurona se le dan los valores (0,1), (1,0) o (1,1), debería dar una salida de 1, y si se le da (0,0), debería dar una salida de 0. La neurona hace esto aplicando una simple operación matemática a la entrada: suma los valores que se le han dado y luego añade su propio valor oculto, que se llama "sesgo". Para empezar, este valor oculto es aleatorio, y lo ajustamos con el tiempo si la neurona no nos da la salida deseada.
Si sumamos valores como (1,1), podemos acabar con números mayores que 1, ¡pero queremos que nuestra salida esté entre 0 y 1! Para resolver esto, podemos aplicar una función que limite nuestra salida real a 0 o 1, incluso si el resultado de las matemáticas de la neurona no estuviera dentro del rango. En redes neuronales más complicadas, aplicamos una función (como la sigmoidea) a la neurona, para que su valor esté entre 0 o 1 (como 0,66), y luego pasamos este valor a la siguiente neurona hasta que necesitemos nuestra salida.
Métodos de aprendizaje
Hay tres formas en que una red neuronal puede aprender: el aprendizaje supervisado, el aprendizaje no supervisado y el aprendizaje por refuerzo. Todos estos métodos funcionan minimizando o maximizando una función de coste, pero cada uno es mejor en determinadas tareas.
Recientemente, un equipo de investigación de la Universidad de Hertfordshire (Reino Unido) utilizó el aprendizaje por refuerzo para que un robot humanoide iCub aprendiera a decir palabras sencillas balbuceando.
Preguntas y respuestas
P: ¿Qué es una red neuronal?
R: Una red neuronal (también llamada RNA o red neuronal artificial) es una especie de software informático, inspirado en las neuronas biológicas. Está formada por células que trabajan juntas para producir un resultado deseado, aunque cada célula individual sólo es responsable de resolver una pequeña parte del problema.
P: ¿Cómo se compara una red neuronal con los cerebros biológicos?
R: Los cerebros biológicos son capaces de resolver problemas difíciles, pero cada neurona sólo es responsable de resolver una parte muy pequeña del problema. Del mismo modo, una red neuronal está formada por células que trabajan juntas para producir un resultado deseado, aunque cada célula individual sólo es responsable de resolver una pequeña parte del problema.
P: ¿Qué tipo de programa puede crear programas artificialmente inteligentes?
R: Las redes neuronales son un ejemplo de aprendizaje automático, en el que un programa puede cambiar a medida que aprende a resolver un problema.
P: ¿Cómo se puede entrenar y mejorar con cada ejemplo para utilizar el aprendizaje profundo?
R: Una red neuronal puede entrenarse y mejorar con cada ejemplo, pero cuanto más grande sea la red neuronal, más ejemplos necesitará para funcionar bien, a menudo necesitando millones o miles de millones de ejemplos en el caso del aprendizaje profundo.
P: ¿Qué se necesita para que el aprendizaje profundo tenga éxito?
R: Para que el aprendizaje profundo tenga éxito se necesitan millones o miles de millones de ejemplos, dependiendo del tamaño de la red neuronal.
P: ¿Cómo se relaciona el aprendizaje automático con la creación de programas artificialmente inteligentes?
R: El aprendizaje automático se relaciona con la creación de programas artificialmente inteligentes porque permite que los programas cambien a medida que aprenden a resolver problemas.
Artículos relacionados
Autor
AlegsaOnline.com Redes neuronales: definición, funcionamiento y aplicaciones en IA Leandro Alegsa
URL: https://es.alegsaonline.com/art/6353
Fuentes
- newscientist.com : "Baby robot learns first words from human teacher"