Aprendizaje profundo: definición, redes neuronales y aplicaciones
Descubre qué es el aprendizaje profundo, cómo funcionan las redes neuronales y sus aplicaciones en visión, voz y NLP. Conceptos, ejemplos y retos actuales.
El aprendizaje profundo (también llamado aprendizaje estructurado profundo o aprendizaje jerárquico) es un tipo de aprendizaje automático, que se utiliza sobre todo con ciertos tipos de redes neuronales. Al igual que otros tipos de aprendizaje automático, las sesiones de aprendizaje pueden ser no supervisadas, semi-supervisadas o supervisadas. En muchos casos, las estructuras se organizan de forma que haya al menos una capa intermedia (o capa oculta), entre la capa de entrada y la de salida.
Algunas tareas, como el reconocimiento y la comprensión del habla, las imágenes o la escritura, son fáciles de realizar para los humanos. Sin embargo, para un ordenador, estas tareas son muy difíciles de realizar. En una red neuronal multicapa (que tiene más de dos capas), la información procesada será más abstracta con cada capa añadida.
Los modelos de aprendizaje profundo se inspiran en el procesamiento de la información y en los patrones de comunicación de los sistemas nerviosos biológicos; son diferentes de las propiedades estructurales y funcionales de los cerebros biológicos (especialmente del cerebro humano) en muchos aspectos, lo que los hace incompatibles con las evidencias de la neurociencia.
Galería de imágenes
3 Imágenes
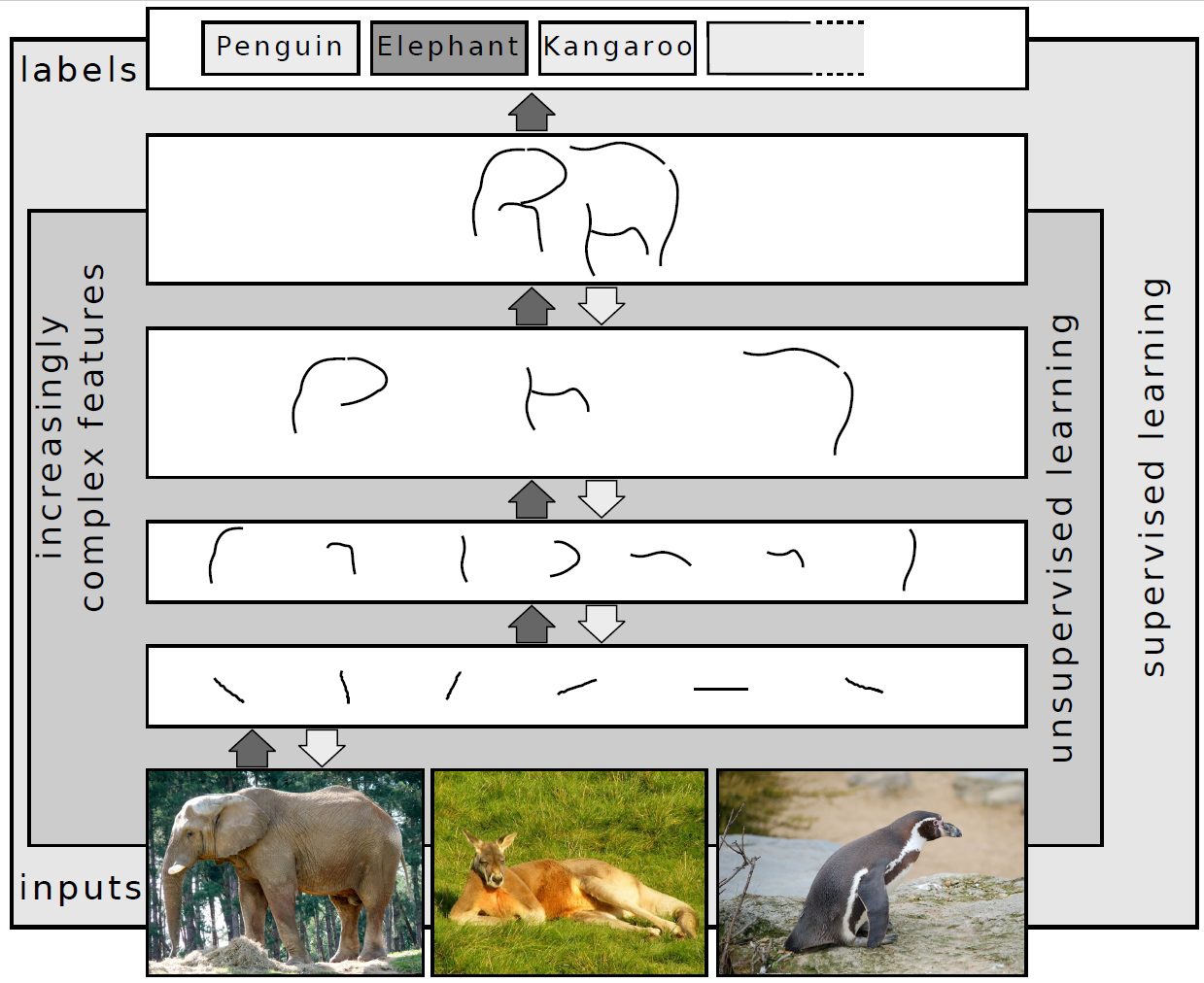
Cómo funcionan las redes profundas
En términos prácticos, una red neuronal profunda está formada por capas de unidades (neuronas artificiales) que realizan operaciones matemáticas sobre los datos de entrada. Cada neurona aplica una combinación lineal de sus entradas seguida por una función de activación (por ejemplo, ReLU, sigmoid o tanh) que introduce no linealidad. El entrenamiento ajusta los parámetros (pesos y sesgos) de la red minimizando una función de pérdida mediante algoritmos de optimización como el descenso por gradiente y sus variantes (SGD, Adam, RMSprop).
El proceso de aprendizaje habitual incluye:
- Propagación hacia delante: cálculo de salidas y pérdida.
- Retropropagación: cálculo de gradientes de la pérdida respecto a cada parámetro.
- Actualización de parámetros: aplicación del optimizador para reducir la pérdida.
Principales arquitecturas
Existen muchas arquitecturas diseñadas para tareas específicas:
- Redes neuronales convolucionales (CNN): eficaces en visión por computador y procesamiento de imágenes, detectan patrones espaciales y son la base de tareas como clasificación, segmentación y detección de objetos.
- Redes recurrentes (RNN) y variantes LSTM/GRU: útiles para datos secuenciales como series temporales o audio; capturan dependencias temporales.
- Transformers: basados en mecanismos de atención, han revolucionado el procesamiento del lenguaje natural (NLP) y se usan cada vez más en visión y audio (p. ej., modelos de lenguaje, traducción, reconocimiento de voz).
- Redes generativas: incluyen GANs (generative adversarial networks), VAEs (variational autoencoders) y modelos de difusión; se usan para generar imágenes, audio y texto.
- Redes profundas totalmente conectadas (MLP): útiles en escenarios con datos tabulares o como componentes dentro de sistemas más grandes.
Entrenamiento y técnicas clave
Para que los modelos profundos funcionen bien en la práctica, se emplean numerosas técnicas:
- Regularización: dropout, weight decay y batch normalization para evitar sobreajuste y estabilizar el entrenamiento.
- Aumento de datos (data augmentation): transformar entradas (rotaciones, recortes, ruido) para mejorar la generalización.
- Transfer learning: reutilizar pesos preentrenados y afinar (fine-tuning) en tareas específicas para reducir necesidad de datos y tiempo de entrenamiento.
- Aprendizaje no supervisado y auto-supervisado: técnicas que permiten explotar grandes cantidades de datos sin etiquetas para aprender representaciones útiles.
- Evaluación: uso de métricas adecuadas (accuracy, precisión/recall, F1, IoU, AUC, BLEU, perplexity, etc.) según la tarea.
Aplicaciones prácticas
El aprendizaje profundo se aplica en numerosos campos:
- Visión por computador: clasificación de imágenes, segmentación semántica, detección de objetos, reconocimiento facial.
- Procesamiento del lenguaje natural (NLP): modelos de lenguaje, traducción automática, resumen automático, respuesta a preguntas, chatbots.
- Reconocimiento y síntesis de voz: conversión voz-texto (ASR) y texto-voz (TTS).
- Medicina: diagnóstico por imagen (radiología, dermatología), análisis de genómica, descubrimiento de fármacos.
- Conducción autónoma y robótica: percepción, planificación y control.
- Sistemas de recomendación: personalización de contenidos y comercio electrónico.
- Generación de contenido: creación de imágenes, música y texto mediante modelos generativos.
Retos, limitaciones y consideraciones éticas
Aunque el aprendizaje profundo ha logrado avances impresionantes, presenta desafíos importantes:
- Necesidad de datos y cómputo: los modelos grandes requieren grandes volúmenes de datos y recursos de hardware (GPUs/TPUs), lo que implica costes y consumo energético.
- Interpretabilidad: las redes profundas suelen ser cajas negras; entender por qué toman una decisión puede ser difícil.
- Sesgos y equidad: si los datos de entrenamiento contienen sesgos, las predicciones pueden perpetuarlos; es necesario auditar y corregir sesgos.
- Privacidad y seguridad: riesgo de filtrar información sensible, ataques adversariales y usos malintencionados.
- Robustez y generalización: las redes pueden fallar ante datos fuera de distribución o ejemplos adversariales.
Para mitigar estos problemas se aplican prácticas como el diseño de conjuntos de datos representativos, técnicas de interpretación (saliency maps, LIME, SHAP), entrenamiento con privacidad (differential privacy), aprendizaje federado y evaluación rigurosa en escenarios del mundo real.
Herramientas y ecosistema
El desarrollo de modelos de aprendizaje profundo se apoya en bibliotecas y marcos de trabajo como TensorFlow, PyTorch, Keras y JAX, que facilitan la construcción, el entrenamiento y la puesta en producción. Además, existen servicios en la nube y hardware especializado (GPUs, TPUs) que aceleran el entrenamiento y la inferencia. También son comunes las bibliotecas para despliegue en dispositivos móviles y en el borde (edge), optimizando latencia y consumo energético.
Tendencias y futuro
Entre las direcciones activas de investigación y aplicación destacan:
- Modelos multimodales que integran texto, imagen y audio.
- Modelos más eficientes en tamaño y consumo (model compression, pruning, quantization).
- Aprendizaje auto-supervisado para aprovechar grandes volúmenes de datos no etiquetados.
- Sistemas más interpretables y seguros para aplicaciones críticas.
- Integración con la ciencia y la ingeniería (p. ej., diseño de fármacos, materiales) y automatización creativa en arte y diseño.
En resumen, el aprendizaje profundo es una rama potente y en rápido desarrollo del aprendizaje automático que permite resolver problemas complejos en múltiples dominios, pero requiere datos, cómputo y una atención constante a cuestiones de ética, robustez y equidad.

Preguntas y respuestas
P: ¿Qué es el aprendizaje profundo?
R: El aprendizaje en profundidad es un tipo de aprendizaje automático que utiliza redes neuronales para procesar la información y que suele organizarse con al menos una capa intermedia (oculta) entre las capas de entrada y salida.
P: ¿Cuáles son los distintos tipos de sesiones de aprendizaje que se utilizan en el aprendizaje profundo?
R: El aprendizaje profundo puede organizarse en sesiones de aprendizaje no supervisado, semisupervisado y supervisado.
P: ¿Cuáles son algunas tareas fáciles de realizar para los humanos pero difíciles para los ordenadores?
R: Tareas como reconocer y comprender el habla, las imágenes o la escritura a mano son fáciles para los humanos pero difíciles de realizar para los ordenadores.
P: ¿Qué le ocurre a la información cuando se procesa en una red neuronal multicapa?
R: En una red neuronal multicapa, la información procesada se vuelve más abstracta con cada capa añadida.
P: ¿En qué se inspiran los modelos de aprendizaje profundo?
R: Los modelos de aprendizaje profundo se inspiran en el procesamiento de la información y en los patrones de comunicación de los sistemas nerviosos biológicos.
P: ¿En qué se diferencian los modelos de aprendizaje profundo de las propiedades de los cerebros biológicos?
R: Los modelos de aprendizaje profundo difieren de las propiedades estructurales y funcionales de los cerebros biológicos, especialmente del cerebro humano, en muchos aspectos, lo que los hace incompatibles con las evidencias de la neurociencia.
P: ¿Cuál es otro término para el aprendizaje profundo?
R: El aprendizaje profundo también se conoce como aprendizaje estructurado profundo o aprendizaje jerárquico.
Artículos relacionados
Autor
AlegsaOnline.com Aprendizaje profundo: definición, redes neuronales y aplicaciones Leandro Alegsa
URL: https://es.alegsaonline.com/art/26216
Fuentes
- ncbi.nlm.nih.gov : "Toward an Integration of Deep Learning and Neuroscience"
- doi.org : 10.3389/fncom.2016.00094
- pubmed.ncbi.nlm.nih.gov : 27683554
- ui.adsabs.harvard.edu : 1996Natur.381..607O
- doi.org : 10.1038/381607a0
- pubmed.ncbi.nlm.nih.gov : 8637596