Modelo relacional de bases de datos: definición, Codd y SQL
Modelo relacional de bases de datos: definición, historia y principios de Codd, implementación en SQL y buenas prácticas para diseñar y consultar datos eficientemente.
El modelo relacional para la gestión de bases de datos es un modelo de base de datos basado en la lógica de predicados de primer orden. Edgar F. Codd lo propuso en 1969. En el modelo relacional de una base de datos, todos los datos se representan en términos de tuplas, agrupadas en relaciones. Una base de datos organizada en términos del modelo relacional se denomina base de datos relacional.
El objetivo del modelo relacional es proporcionar un método declarativo para especificar los datos y las consultas: los usuarios indican directamente qué información contiene la base de datos y qué información quieren obtener de ella. La estructura física en la que se almacenan los datos y la tarea de responder a las peticiones de los usuarios se deja en manos del sistema gestor de bases de datos, y no es visible para el usuario. Esta separación favorece la independencia de datos (lógica y física) y simplifica el mantenimiento.
Galería de imágenes
1 Imagen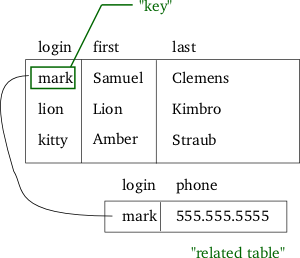
Definición y componentes básicos
En términos formales, una relación es un conjunto (o, en la práctica, una multitudes en SQL) de tuplas donde cada tupla es una lista ordenada de valores asociados a atributos. Los elementos esenciales son:
- Esquema: define el conjunto de atributos (columnas) y los dominios (tipos) de valores permitidos.
- Tuplas: registros o filas que contienen valores para cada atributo.
- Relación: el conjunto de todas las tuplas válidas para un esquema dado.
- Clave primaria: atributo(s) que identifican de forma única una tupla dentro de una relación.
- Claves externas y restricciones de integridad referencial: relaciones entre tablas que mantienen la coherencia de los datos.
Edgar F. Codd y sus aportes
Edgar F. Codd formuló el modelo relacional con base en la lógica de predicados y propuso principios para que un sistema de gestión de bases de datos cumpliera el paradigma relacional. Entre sus aportes destacan:
- La formalización del concepto de relación como estructura matemática (con raíz en la teoría de conjuntos y el cálculo relacional).
- La idea de un lenguaje de consulta basado en álgebra relacional y en el cálculo relacional (dos formalismos equivalentes en expresividad).
- Un conjunto de reglas y principios (conocidas como las reglas de Codd) que definen propiedades deseables en un sistema relacional, como el manejo uniforme de datos mediante relaciones y la independencia entre representación física y lógica.
Álgebra relacional y cálculo relacional
Para especificar consultas, Codd propuso dos enfoques equivalentes:
- Álgebra relacional: un conjunto de operadores (selección, proyección, unión, diferencia, producto cartesiano, renombrado, y operadores derivados como join e intersección) que toman relaciones como entrada y producen relaciones como salida. Es imperativa en el sentido de que describe cómo combinar relaciones.
- Cálculo relacional (tuple o domain calculus): un enfoque declarativo basado en lógica de predicados donde las consultas se expresan como fórmulas lógicas que describen propiedades de las tuplas buscadas.
Estos formalismos son la base teórica sobre la que se construyó el desarrollo de lenguajes de consulta prácticas como SQL.
SQL y las desviaciones prácticas del modelo
La mayoría de sistemas de bases de datos relacionales implementan SQL como lenguaje de definición y manipulación de datos. Sin embargo, SQL introduce varias diferencias prácticas respecto al modelo relacional puro propuesto por Codd, entre las cuales destacan:
- Multiconjunto (bag semantics): SQL permite filas duplicadas a menos que se indique lo contrario (por ejemplo con DISTINCT), mientras que el modelo relacional clásico considera relaciones como conjuntos sin duplicados.
- Valores NULL: SQL incluye el concepto de NULL para representar información desconocida o no aplicable; esto complica la lógica (trivalente) y la semántica matemática del modelo relacional.
- Orden: en SQL pueden especificarse ordenaciones (ORDER BY). En el modelo relacional puro, las relaciones son conjuntos no ordenados.
- Tipos y extensiones: SQL incorpora tipos complejos, procedimientos almacenados, triggers y otras extensiones que van más allá del núcleo relacional.
Debido a estas y otras diferencias, muchos autores consideran que los SGBD SQL son una aproximación práctica y pragmática al modelo relacional, con compromisos de ingeniería para rendimiento, usabilidad y compatibilidad.
Restricciones de integridad y ACID
Las bases de datos relacionales soportan mecanismos para garantizar la integridad de los datos:
- Integridad de entidad: las claves primarias no deben ser nulas y deben identificar de forma única cada tupla.
- Integridad referencial: las claves externas deben referenciar tuplas existentes o admitir reglas de borrado/actualización en cascada.
- Restricciones de dominio y CHECK: limitan los valores admitidos por atributos.
- Transacciones y propiedades ACID: Atomicidad, Consistencia, Aislamiento y Durabilidad, para asegurar que las operaciones múltiples sobre la base de datos se ejecuten de forma segura y coherente.
Normalización
El modelo relacional incluye principios de diseño para reducir redundancias y anomalías de actualización mediante la normalización. Las formas normales más citadas son:
- Primera forma normal (1NF): atomicidad en los atributos (no atributos repetidos o anidados).
- Segunda y tercera forma normal (2NF, 3NF): eliminación de dependencias parciales y dependencias transitivas.
- Forma normal de Boyce-Codd (BCNF): una versión más estricta que evita ciertas anomalías remanentes.
La normalización mejora la consistencia pero en la práctica a veces se denormaliza deliberadamente para optimizar el rendimiento de consultas intensivas.
Ventajas y limitaciones
Ventajas principales:
- Declaratividad: el usuario describe qué datos necesita y no cómo obtenerlos.
- Independencia de datos: cambios en almacenamiento físico no afectan a las consultas lógicas.
- Integridad y consistencia: mecanismos robustos para mantener reglas de negocio y restricciones.
- Madurez y ecosistema: herramientas, optimizadores de consultas y amplia experiencia industrial.
Limitaciones y retos:
- Escalabilidad horizontal (sharding) más compleja que en modelos NoSQL para cargas masivas distribuidas.
- Alto coste de joins complejos en datasets muy grandes.
- Impedance mismatch entre modelos de objetos en aplicaciones y el modelo relacional —a menudo abordado mediante Object-Relational Mapping (ORM).
Implementaciones y evolución
Existen numerosos sistemas gestores relacionales comerciales y de código abierto (por ejemplo, Oracle, Microsoft SQL Server, PostgreSQL, MySQL/MariaDB). Con el tiempo surgieron extensiones como objetos-relacionales, column stores y optimizaciones para datos analíticos. Además, la aparición de bases de datos NoSQL no anuló el uso del modelo relacional, sino que amplió el abanico de soluciones: hoy se elige la tecnología según requisitos de consistencia, rendimiento y escalabilidad.
Resumen
El modelo relacional es una base teórica y práctica para organizar datos mediante relaciones (tablas) y tuplas (filas), con un fuerte énfasis en la integridad, la independencia de datos y la expresividad declarativa. Edgar F. Codd lo formalizó usando la lógica de predicados y sentó las bases para lenguajes de consulta y sistemas que han dominado el manejo de datos durante décadas. SQL es la implementación práctica más extendida, aunque incorpora decisiones prácticas (NULLs, duplicados, orden) que suponen desviaciones respecto al modelo relacional puro.


Preguntas y respuestas
P: ¿Qué es el modelo relacional para la gestión de bases de datos?
R: El modelo relacional para la gestión de bases de datos es un modelo de base de datos basado en la lógica de predicados de primer orden.
P: ¿Quién propuso el modelo relacional para la gestión de bases de datos y cuándo se propuso?
R: Edgar F. Codd propuso el modelo relacional para la gestión de bases de datos en 1969.
P: ¿Cómo se representan los datos en el modelo relacional de una base de datos?
R: En el modelo relacional de una base de datos, todos los datos se representan en términos de tuplas, agrupadas en relaciones.
P: ¿Cómo se denomina una base de datos organizada en términos del modelo relacional?
R: Una base de datos organizada en términos del modelo relacional se denomina base de datos relacional.
P: ¿Cuál es la finalidad del modelo relacional?
R: El propósito del modelo relacional es proporcionar un método declarativo para especificar datos y consultas.
P: ¿Qué lenguaje utilizan la mayoría de las bases de datos relacionales?
R: La mayoría de las bases de datos relacionales utilizan el lenguaje de definición de datos y consultas SQL.
P: ¿Cómo se corresponden la tabla, el contenido de la tabla, las restricciones clave, otras restricciones y las consultas SQL con los predicados en el modelo relacional?
R: En el modelo relacional, una tabla en un esquema de base de datos SQL corresponde a una variable predicada; el contenido de una tabla a una relación; las restricciones clave, otras restricciones y las consultas SQL corresponden a predicados.
Artículos relacionados
Autor
AlegsaOnline.com Modelo relacional de bases de datos: definición, Codd y SQL Leandro Alegsa
URL: https://es.alegsaonline.com/art/82000
Fuentes
- acm.org : "A Relational Model of Data for Large Shared Data Banks"
- doi.org : 10.1145/362384.362685
- knowledge.fhwa.dot.gov : Data Integration Glossary