Ley de los grandes números: definición, explicación y ejemplos en estadística
Ley de los grandes números: descubre cómo la media converge al valor esperado con ejemplos prácticos, gráficos y aplicaciones estadísticas para entender su demostración y uso.
La ley de los grandes números (LLN) es un teorema de la estadística. Considere un proceso en el que se producen resultados aleatorios. Por ejemplo, una variable aleatoria se observa repetidamente. Entonces, la media de los valores observados será estable, a largo plazo. Esto significa que, a largo plazo, la media de los valores observados se acercará cada vez más al valor esperado.
Al lanzar los dados, los números 1, 2, 3, 4, 5 y 6 son resultados posibles. Todos son igualmente probables. La media poblacional (o "valor esperado") de los resultados es:
(1 + 2 + 3 + 4 + 5 + 6) / 6 = 3.5.
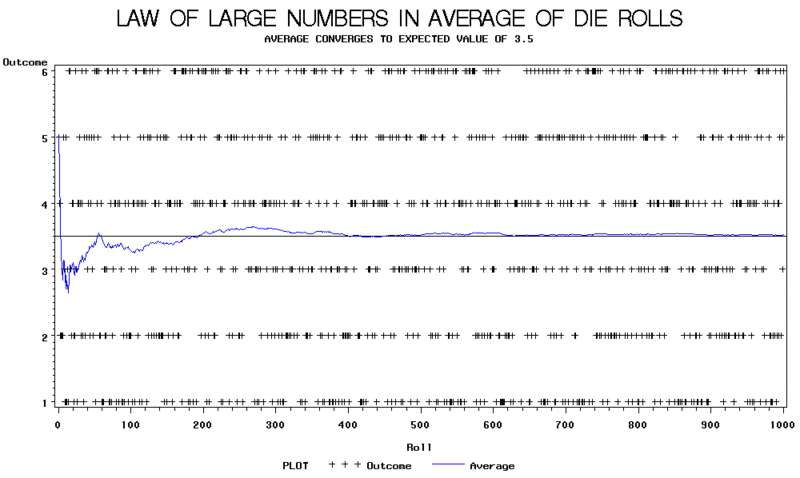
El siguiente gráfico muestra los resultados de un experimento de lanzamientos de un dado. En este experimento se puede ver que la media de las tiradas del dado varía mucho al principio. Tal y como predice el LLN, la media se estabiliza en torno al valor esperado de 3,5 a medida que el número de observaciones se hace grande.
Galería de imágenes
3 Imágenes


¿Qué dice exactamente la ley de los grandes números?
De forma informal, la LLN establece que la media aritmética de muchas observaciones independientes de una misma variable aleatoria con esperanza finita tiende a acercarse al valor esperado real de esa variable cuando el número de observaciones crece indefinidamente.
Usando notación habitual: sean X1, X2, ..., Xn observaciones independientes e idénticamente distribuidas (i.i.d.) con esperanza E[X1] = μ. Definimos la media muestral como
X̄n = (X1 + X2 + ... + Xn) / n.
La ley de los grandes números afirma que X̄n se aproxima a μ cuando n → ∞.
Versiones formales
- Ley débil de los grandes números (WLLN): X̄n converge en probabilidad a μ. Es decir, para todo ε > 0, P(|X̄n − μ| > ε) → 0 cuando n → ∞. Una demostración estándar usa la desigualdad de Chebyshev cuando las varianzas son finitas.
- Ley fuerte de los grandes números (SLLN): X̄n converge casi seguramente (c.s.) a μ. Esto es más fuerte: P(límite de X̄n = μ) = 1. Hay demostraciones que usan el lema de Borel–Cantelli o teoremas de Kolmogorov bajo hipótesis de independencia y esperanza finita.
Condiciones habituales y excepciones
- Las hipótesis más comunes que garantizan la LLN son independencia (o cierta forma de dependencia débil), idéntica distribución y esperanza finita (E[|X1|] < ∞). Para la WLLN muchas veces basta varianza finita.
- No aplica cuando la variable tiene esperanza infinita o no está bien definida: por ejemplo, la distribución de Cauchy no satisface la LLN clásica y la media muestral no converge al centro porque la esperanza no existe.
Demostración intuitiva y velocidad de convergencia
Una explicación simple con varianzas finitas: si Var(Xi) = σ2 < ∞, entonces Var(X̄n) = σ2/n. Al aumentar n la varianza de la media tiende a 0, de modo que la probabilidad de desviaciones grandes se hace pequeña (Chebyshev). Esto da la WLLN. La SLLN requiere argumentos más finos (por ejemplo, control con Borel–Cantelli).
La velocidad a la que X̄n se acerca a μ no está dada por la LLN, pero el teorema del límite central (TLG) completa la imagen: las fluctuaciones típicas alrededor de μ son del orden 1/√n y (X̄n − μ)·√n tiende en distribución a una normal con varianza σ2. Por eso para reducir el error típico a la mitad se necesitan 4 veces más observaciones.
Ejemplos prácticos
- Lanzamiento de un dado: como ya se muestra arriba, la media de las caras tiende a 3,5 conforme aumentan los lanzamientos.
- Monedas: la proporción de caras en n lanzamientos tiende a 0.5.
- Encuestas y muestreo: al aumentar el tamaño de la muestra la media muestral (por ejemplo, la proporción que apoya una idea) se acerca al verdadero porcentaje poblacional.
- Seguros y finanzas: grandes carteras de pólizas o muchos riesgos independientes permiten que la pérdida media sea predecible y manejable.
- Integración por Monte Carlo: el promedio de muchas simulaciones de una función aleatoria aproxima su esperanza, que en muchos casos corresponde a una integral.
Errores y malentendidos comunes
- Gambler’s fallacy (falacia del jugador): creer que resultados pasados influyen en resultados independientes venideros. La LLN no implica corrección a corto plazo: la media se estabiliza solo a largo plazo.
- No garantiza igualdad exacta en muestras finitas: para cualquier n finito pueden darse desviaciones considerables. La LLN habla del comportamiento cuando n tiende a infinito.
- Confusión con el TLG: la LLN habla de convergencia del promedio al valor esperado; el TLG describe la distribución de las desviaciones escaladas (√n) y permite crear intervalos de confianza.
¿Cuántas observaciones hacen falta?
No existe un número universal de observaciones que garantice “suficiente precisión”; depende de la variabilidad de la variable y del margen de error tolerable. La desigualdad de Chebyshev permite dar una cota conservadora:
P(|X̄n − μ| ≥ ε) ≤ Var(X1) / (n ε2).
Despejando, para que la probabilidad de desviación mayor que ε sea como máximo δ, basta con elegir
n ≥ Var(X1) / (δ ε2).
En la práctica se usan estimaciones de varianza y el TLG para calcular tamaños muestrales más precisos y menos conservadores.
Breve esbozo de demostración (WLLN con Chebyshev)
- Sea X1,...,Xn i.i.d. con esperanza μ y varianza σ2. Entonces E[X̄n] = μ y Var(X̄n) = σ2/n.
- Por la desigualdad de Chebyshev, P(|X̄n − μ| ≥ ε) ≤ Var(X̄n)/ε2 = σ2/(n ε2).
- Al hacer n → ∞ la cota σ2/(n ε2) → 0, por lo que P(|X̄n − μ| ≥ ε) → 0. Esto demuestra la convergencia en probabilidad.
Aplicaciones prácticas
- Diseño de encuestas y control de calidad: permite confiar en promedios muestrales cuando la muestra es suficientemente grande.
- Simulaciones y métodos numéricos (Monte Carlo): justifica el uso de promedios de repeticiones aleatorias para aproximar esperanzas e integrales.
- Gestión de riesgos: las compañías pueden diversificar riesgos para que la pérdida promedio sea estable y predecible.
Conclusión
La ley de los grandes números es un pilar de la estadística que conecta el comportamiento observable en muestras grandes con parámetros poblacionales (el valor esperado). Es fundamental para entender por qué los promedios muestrales son estimadores útiles y por qué la aleatoriedad “se apacigua” cuando se agregan muchas observaciones. Sin embargo, sus conclusiones son asintóticas: en muestras pequeñas pueden darse grandes desviaciones, y existen distribuciones (por ejemplo, con esperanza inexistente) donde la ley clásica no se aplica.
Historia
Jacob Bernoulli describió por primera vez la LLN. Según él, era tan simple que hasta el hombre más estúpido sabe instintivamente que es cierto. A pesar de ello, tardó más de 20 años en desarrollar una buena prueba matemática. Una vez que la encontró, publicó la prueba en Ars Conjectandi (El arte de conjeturar) en 1713. Lo llamó "Teorema de Oro". En 1835, S.D.Poisson lo describió con el nombre de "La ley de los grandes números". A partir de entonces, se conoció con ambos nombres, pero la "Ley de los grandes números" es la más utilizada.
Otros matemáticos también contribuyeron a mejorar la ley. Algunos de ellos fueron Chebyshev, Markov, Borel, Cantelli y Kolmogorov. Tras estos estudios, ahora existen dos formas diferentes de la ley: Una se llama ley "débil" y la otra ley "fuerte". Estas formas no describen leyes diferentes. Tienen formas diferentes de describir la convergencia de la probabilidad observada o medida a la probabilidad real. La forma fuerte de la ley implica la débil.
Preguntas y respuestas
P: ¿Qué es la ley de los grandes números?
R: La ley de los grandes números es un teorema estadístico que afirma que si se observa repetidamente un proceso aleatorio, la media de los valores observados será estable a largo plazo.
P: ¿Qué significa la ley de los grandes números?
R: La ley de los grandes números significa que a medida que aumenta el número de observaciones, la media de los valores observados se acercará cada vez más al valor esperado.
P: ¿Qué es un valor esperado?
R: Un valor esperado es la media poblacional de los resultados de un proceso aleatorio.
P: ¿Cuál es el valor esperado de lanzar un dado?
R: El valor esperado de lanzar un dado es la suma de los resultados posibles dividida por el número de resultados: (1+2+3+4+5+6)/6=3,5.
P: ¿Qué muestra el gráfico del texto en relación con la ley de los grandes números?
R: El gráfico muestra que la media de las tiradas varía mucho al principio, pero como predice la LLN, la media se estabiliza en torno al valor esperado de 3,5 a medida que el número de observaciones se hace grande.
P: ¿Cómo se aplica la ley de los grandes números al lanzamiento de dados?
R: La ley de los grandes números se aplica al lanzamiento de dados porque a medida que aumenta el número de lanzamientos, la media de los lanzamientos se acercará cada vez más al valor esperado de 3,5.
P: ¿Por qué es importante la ley de los grandes números en estadística?
R: La ley de los grandes números es importante en estadística porque proporciona una base teórica para la idea de que los datos tienden a promediar a lo largo de un gran número de observaciones. Es el fundamento de muchos métodos estadísticos, como los intervalos de confianza y las pruebas de hipótesis.
Artículos relacionados
Autor
AlegsaOnline.com Ley de los grandes números: definición, explicación y ejemplos en estadística Leandro Alegsa
URL: https://es.alegsaonline.com/art/56403