Ajuste de curvas: definición y técnicas (interpolación, suavizado, regresión)
Ajuste de curvas: aprende definición y técnicas clave—interpolación, suavizado y regresión—para modelar, visualizar y predecir datos con rigor estadístico.
El ajuste de curvas consiste en construir una función matemática que se ajuste lo mejor posible a un conjunto de puntos de datos.
El ajuste de la curva puede implicar la interpolación o el suavizado. La interpolación requiere un ajuste exacto de los datos. Con el suavizado, se construye una función "suave" que se ajusta a los datos de forma aproximada. Un tema relacionado es el análisis de regresión, que se centra más en cuestiones de inferencia estadística, como el grado de incertidumbre presente en una curva que se ajusta a datos observados con errores aleatorios.
Las curvas ajustadas pueden utilizarse para ayudar a la visualización de los datos, para adivinar los valores de una función cuando no hay datos disponibles y para resumir las relaciones entre dos o más variables. La extrapolación se refiere al uso de una curva ajustada más allá del rango de los datos observados. Está sujeta a un grado de incertidumbre, ya que puede reflejar el método utilizado para construir la curva tanto como los datos observados.
Galería de imágenes
3 Imágenes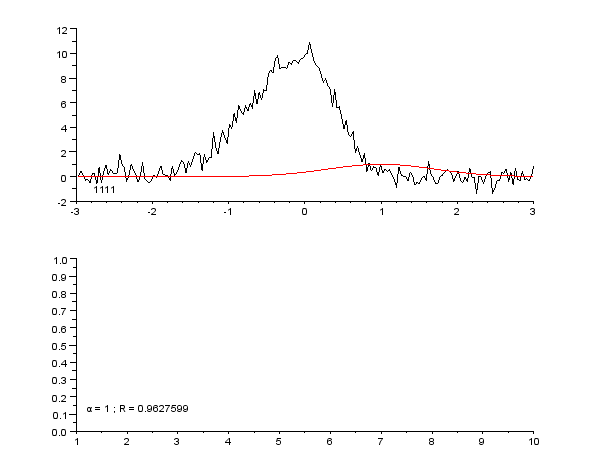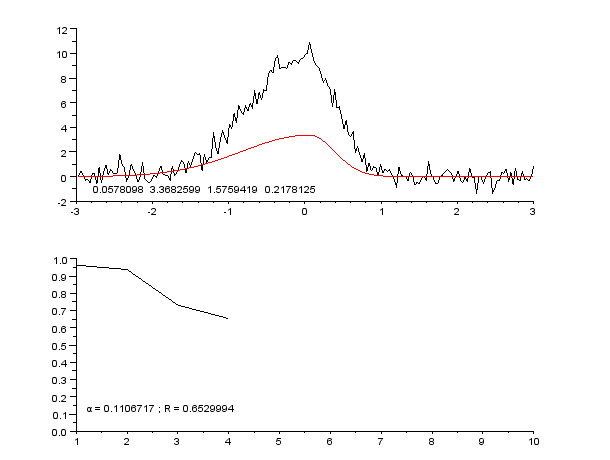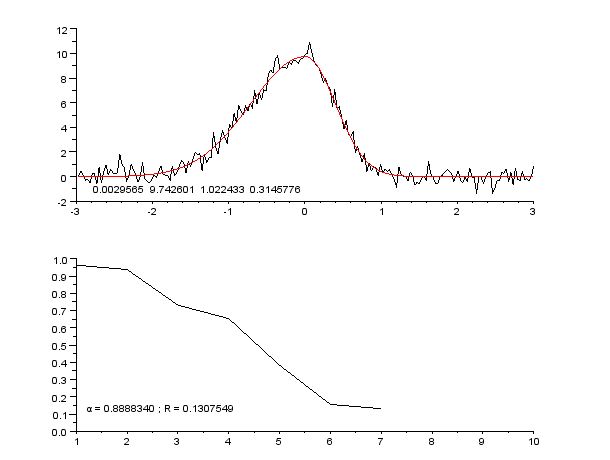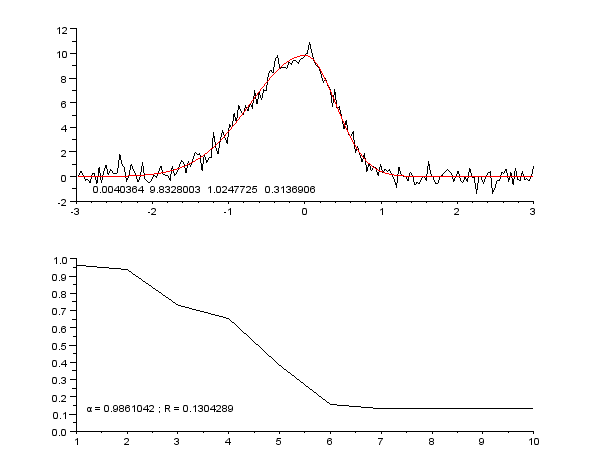


Técnicas comunes de ajuste de curvas
- Interpolación: construye una función que pasa exactamente por todos los puntos de datos. Ejemplos:
- Interpolación polinómica (grado n−1 para n puntos).
- Spline cúbico: piezas polinómicas suaves que minimizan oscilaciones; muy usado para datos no uniformes.
- Interpolación con funciones base (p. ej., B‑splines).
- Suavizado (smoothing): busca una curva que capture la tendencia general sin seguir el ruido. Ejemplos:
- Media móvil y filtros simples.
- Kernel smoothing (suavizado por núcleos) con selección de ancho de banda.
- LOESS/LOWESS: regresión local ponderada.
- Smoothing splines: minimizan una suma de errores más un término de regularización (p. ej., integral de la segunda derivada al cuadrado).
- Análisis de regresión: modelos paramétricos o semiparamétricos que explican la relación entre variables y permiten inferencia estadística.
- Regresión lineal (simple y múltiple): ajuste por mínimos cuadrados ordinarios (OLS).
- Regresión polinómica y modelos no lineales.
- Regresión regularizada: ridge, LASSO (control de complejidad y multicolinealidad).
- Regresión robusta (menos sensible a valores atípicos).
Conceptos matemáticos y criterios de ajuste
- Objetivo típico: minimizar una medida de error, p. ej., la suma de cuadrados residuales S = Σ (y_i − f(x_i))^2.
- Regularización: añadir un término como λ ∫ (f''(x))^2 dx o λ||β||^2 para penalizar curvas demasiado complejas y evitar sobreajuste.
- Selección de parámetros (grado del polinomio, número de nudos en splines, ancho de banda en kernels, λ en regularización) se suele hacer mediante validación cruzada o criterios de información (AIC, BIC, GCV).
Evaluación y validación del ajuste
- Gráficos de residuos: comprobar patrones no aleatorios, heterocedasticidad o valores atípicos.
- Métricas de bondad de ajuste: R², R² ajustado, RMSE (error cuadrático medio), MAE (error absoluto medio).
- Validación cruzada (k‑fold, leave‑one‑out) para estimar el error fuera de muestra y evitar sobreajuste.
- Intervalos de confianza y pruebas estadísticas en el contexto de regresión para cuantificar incertidumbre.
Consideraciones prácticas y recomendaciones
- Evitar polinomios de grado muy alto: suelen oscilar (Runge) y extrapolar mal. Las splines y modelos locales suelen ser más estables.
- Escalar y centrar variables numéricas cuando se usan métodos basados en regularización o en bases polinómicas para mejorar la estabilidad numérica.
- Elegir el método según el objetivo: interpolación exacta para reconstrucción sin ruido; suavizado o regresión para datos ruidosos y predicción.
- Comprobar la sensibilidad del ajuste cambiando el parámetro de suavizado o el número de nudos; usar validación cruzada para seleccionar parámetros.
- Documentar supuestos (independencia de errores, homocedasticidad, linealidad en parámetros) cuando se hagan inferencias estadísticas.
Riesgos al extrapolar
La extrapolación (usar la curva fuera del rango observado) aumenta la incertidumbre. La forma de la curva fuera del intervalo observado depende muchas veces más del modelo elegido que de la información contenida en los datos, por lo que:
- Evitar extrapolar demasiado lejos sin teoría que respalde la forma funcional.
- Comparar varios modelos y cuantificar la variabilidad de las predicciones fuera de muestra.
Aplicaciones típicas
- Ingeniería: calibración de sensores, modelado de comportamiento físico.
- Ciencias naturales: ajuste de curvas experimentales, interpolación de series temporales.
- Economía y finanzas: suavizado de series temporales, modelos de regresión para predicción.
- Medicina y biología: dosis‑respuesta, curvas de crecimiento, análisis de datos experimentales.
Resumen práctico
- Defina el objetivo: interpolación exacta, suavizado descriptivo o predicción inferencial.
- Elija una familia de modelos adecuada (polinomios bajos, splines, métodos locales, modelos paramétricos).
- Use regularización y validación cruzada para controlar la complejidad.
- Evalúe residuales y métricas de error; tenga cautela al extrapolar.
Con estos principios y técnicas podrá seleccionar y ajustar curvas de forma robusta, interpretando correctamente la incertidumbre asociada y evitando errores comunes como el sobreajuste o la confianza excesiva en predicciones fuera del rango observado.

Preguntas y respuestas
P: ¿Qué es el ajuste de curvas?
R: El ajuste de curvas es el proceso de crear una función matemática que se ajuste lo mejor posible a un conjunto de puntos de datos.
P: ¿Cuáles son los dos tipos de ajuste de curvas?
R: Los dos tipos de ajuste de curvas son la interpolación y el suavizado.
P: ¿Qué es la interpolación?
R: La interpolación es un tipo de ajuste de curvas que requiere un ajuste exacto a los datos.
P: ¿Qué es el suavizado?
R: El suavizado es un tipo de ajuste de curvas que construye una función "suave" que se ajusta aproximadamente a los datos.
P: ¿Qué es el análisis de regresión?
R: El análisis de regresión es un tema relacionado que se centra en cuestiones de inferencia estadística, como cuánta incertidumbre hay en una curva que se ajusta a datos observados con errores aleatorios.
P: ¿Cuáles son algunos usos de las curvas ajustadas?
R: Las curvas ajustadas pueden utilizarse para ayudar a visualizar datos, adivinar valores de una función cuando no se dispone de datos y resumir relaciones entre dos o más variables.
P: ¿Qué es la extrapolación?
R: La extrapolación es el uso de una curva ajustada más allá del rango de los datos observados. Sin embargo, está sujeta a cierto grado de incertidumbre, ya que puede reflejar el método utilizado para construir la curva tanto como los datos observados.
Artículos relacionados
Autor
AlegsaOnline.com Ajuste de curvas: definición y técnicas (interpolación, suavizado, regresión) Leandro Alegsa
URL: https://es.alegsaonline.com/art/24757
Fuentes
- books.google.com : The Signal and the Noise
- books.google.com : Data Preparation for Data Mining
- books.google.com : pg 69