Algoritmos de caché: qué son, cómo funcionan y tipos (LRU, LFU, ARC)
Descubre qué son y cómo funcionan los algoritmos de caché (LRU, LFU, ARC), sus ventajas, ejemplos y cómo optimizan la tasa de aciertos y la latencia.
Un algoritmo de caché es un algoritmo empleado para gestionar los contenidos de una caché o de un conjunto de datos en memoria. Cuando la caché está llena, el algoritmo decide qué elemento debe ser eliminado para dejar espacio a nuevos datos. Dos métricas clave son la tasa de aciertos (qué porcentaje de solicitudes se puede servir directamente desde la caché) y la latencia (cuánto tiempo tarda en recuperarse un elemento desde la caché). En la práctica, los algoritmos de caché buscan un equilibrio entre maximizar la tasa de aciertos y minimizar la latencia y el coste de mantenimiento del propio algoritmo.
Galería de imágenes
7 Imágenes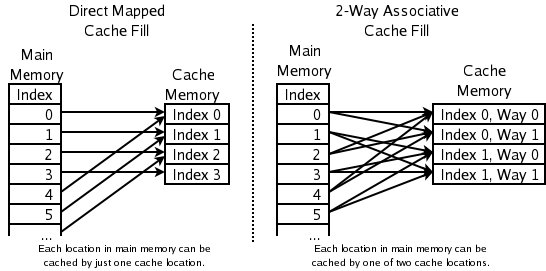



Principio óptimo y limitaciones prácticas
El algoritmo ideal sería aquel que, al conocer el futuro, eliminara siempre el elemento que no se va a necesitar durante el mayor tiempo posible. Ese resultado óptimo se conoce como el algoritmo óptimo de Belady o el algoritmo clarividente. Como en general no es posible predecir el acceso futuro en sistemas reales, el algoritmo clarividente sirve como límite teórico: tras pruebas y simulación se puede comparar la eficacia de un algoritmo práctico frente a ese mínimo óptimo.
Algoritmos populares
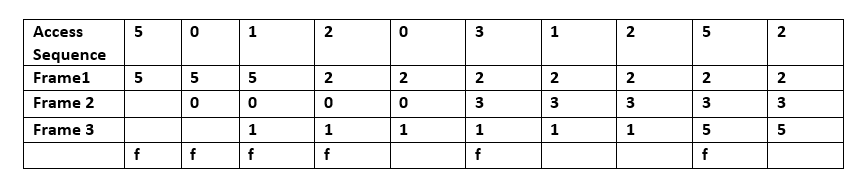
- Least Recently Used (LRU): elimina primero el elemento menos recientemente usado. Requiere llevar un historial del orden de accesos; implementaciones exactas usan listas enlazadas o pilas virtuales, o bits de edad por línea. LRU puede ser caro en coste de mantenimiento si se busca exactitud en cada acceso. LRU forma parte de una familia de algoritmos de caché que incluye variantes como 2Q (Theodore Johnson y Dennis Shasha) y LRU/K (Pat O'Neil, Betty O'Neil y Gerhard Weikum).
- Most Recently Used (MRU): elimina primero el elemento usado más recientemente. Aunque contraintuitivo, en ciertos patrones de acceso (por ejemplo, streaming donde los elementos no se volverán a leer pronto) MRU puede ser superior. Este mecanismo se usa a veces en cachés de bases de datos.
- Pseudo-LRU (PLRU): aproximación a LRU que reduce costes. En vez de mantener un orden completo, PLRU usa un pequeño número de bits por conjunto (por ejemplo, un bit por línea o una estructura de árbol) para elegir un candidato a expulsar. Es común en cachés hardware donde la LRU exacta sería demasiado costosa.
- Conjunto asociativo de 2 vías: en cachés de CPU de alta velocidad se usan conjuntos con dos líneas; la dirección determina el conjunto y la política de reemplazo elige entre las dos líneas (habitualmente se descarta la menos recientemente usada). Esto solo requiere un bit por par de líneas para indicar la LRU dentro del par.
- Caché de mapeo directo: la forma más simple y rápida: cada dirección mapea a una única posición fija en la caché; al traer un nuevo elemento, se sobrescribe lo que había. Muy rápido pero sufre más conflictos.
- Least Frequently Used (LFU): contabiliza la frecuencia de acceso a cada elemento y expulsa los menos usados. Sin mecanismos de envejecimiento, LFU puede «quedarse atascado» con objetos populares en el pasado que ya no se usan (cache pollution).
- Adaptive Replacement Cache (ARC): combina y equilibra dinámicamente criterios de recencia (LRU) y frecuencia (LFU). ARC ajusta automáticamente su comportamiento según la carga de trabajo para mejorar el rendimiento global.
- Algoritmo de almacenamiento en caché de colas múltiples (MQ): propuesta por Y. Zhou, J.F. Philbin y Kai Li que organiza los elementos en múltiples colas según su uso para capturar distintos grados de recencia y frecuencia.
Otras implementaciones y aproximaciones
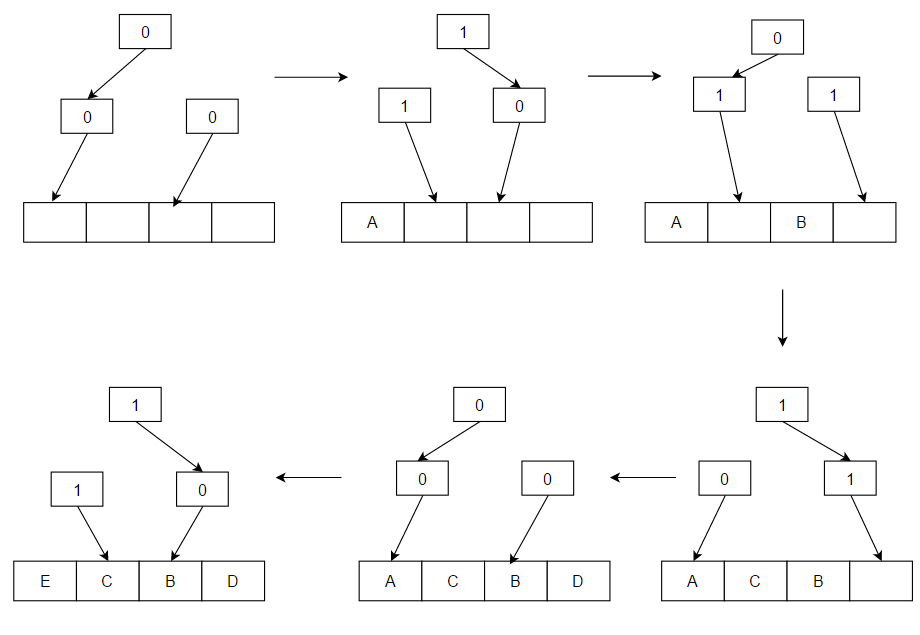
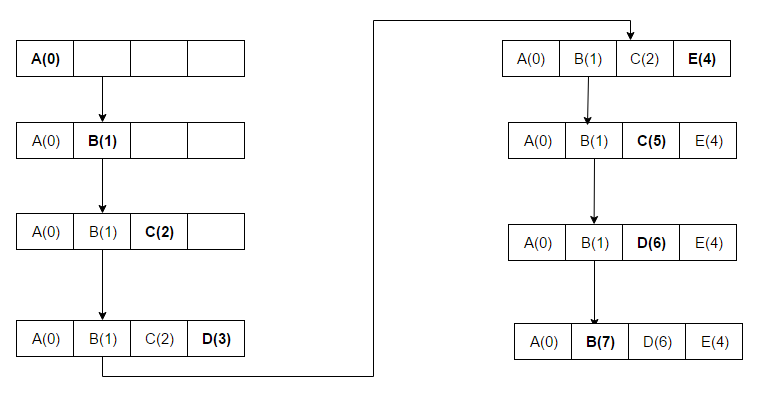
- Clock (Segundo intento): alternativa eficiente a LRU en software/hardware. Mantiene un puntero circular y un bit de referencia por entrada; al reemplazar, hace una pasada para encontrar una entrada con bit de referencia a 0, dándole una segunda oportunidad a las que tienen bit a 1. Es simple y de bajo coste.
- LRU-K y 2Q: variantes de LRU que consideran los últimos K accesos para cada elemento (LRU-K) o usan dos colas (reciente y frecuente) para separar accesos de una sola vez de los repetidos (2Q).
- PLRU por árbol: usado en caches asociativas en hardware, mantiene un árbol de bits que permite elegir una vía víctima con coste muy bajo.
- LFU con envejecimiento: para evitar que los objetos antiguos «conquisten» la caché, se aplica decaimiento periódico a los contadores de frecuencia (p. ej. dividir contadores por 2 cada cierto tiempo).
Consideraciones prácticas al elegir un algoritmo
- Coste de obtención: priorizar guardar elementos caros de reconstruir (p. ej. consultas remotas, cálculos intensivos). Algunos algoritmos son cost-aware (conscientes del coste).
- Tamaño variable de objetos: cuando los elementos ocupan distinto espacio conviene políticas que tengan en cuenta el tamaño (por ejemplo, GreedyDual-Size o variantes que maximizan aciertos por byte).
- Caducidad y TTL: muchas cachés gestionan expiraciones (news, DNS, navegadores). Los objetos pueden ser eliminados por vencimiento más que por política de reemplazo.
- Patrones de acceso: acceso secuencial largo, trabajo con «hot spots», o accesos aleatorios favorecen distintas políticas. Por ejemplo, flujos secuenciales largos pueden degradar LRU pero funcionar bien con MRU o con algoritmos que detectan streaming.
- Métricas relevantes: además de tasa de aciertos y latencia, hay que medir tasa de fallos, coste/beneficio de cada acierto (latencia evitada), y sobrecarga de CPU/memoria del propio algoritmo.
- Política de escritura: write-through vs write-back afecta coherencia y coste de I/O; la estrategia de actualización o invalidación de cachés distribuidas influye en el diseño global.
Coherencia entre múltiples cachés
Existen varios algoritmos y protocolos para mantener la coherencia de la caché cuando hay varias cachés que contienen las mismas datos (por ejemplo, CPUs con cachés privadas o servidores con caches distribuidas). En arquitecturas multiprocesador se emplean protocolos de coherencia como MSI/MESI y variantes que usan operaciones de invalidación o actualización para garantizar que las escrituras sean vistas de forma consistente. En entornos distribuidos (cache clusters, CDN), se usan estrategias de invalidación, puesta en marcha de TTL, o protocolos de consistencia eventual según los requerimientos de la aplicación.
Cómo elegir y evaluar
La elección depende de:
- Patrón de acceso (recencia frente a frecuencia).
- Tamaño de la caché y latencia objetivo.
- Coste de cálculo del propio algoritmo (CPU y memoria extra).
- Necesidad de coherencia y políticas de escritura.
- Distribución de tamaños y coste de obtención de los objetos.
Para evaluar, se recomienda simular con trazas reales o perfilar en producción: medir tasa de aciertos, latencia media y percentiles, uso de recursos y efecto sobre la carga de backend. Muchas implementaciones prácticas combinan heurísticas soportadas por métricas en tiempo real (por ejemplo, usar ARC o MQ en sistemas generales, PLRU/clock en hardware) para adaptarse a cargas cambiantes.

Preguntas y respuestas
P: ¿Qué es un algoritmo de caché?
R: Un algoritmo de caché es un algoritmo utilizado para gestionar una caché o un grupo de datos. Decide qué elemento debe eliminarse de la caché cuando ésta está llena.
P: ¿Qué es la tasa de aciertos?
R: La tasa de aciertos describe la frecuencia con la que una solicitud puede ser servida desde la caché.
P: ¿Qué describe la latencia?
R: La latencia describe durante cuánto tiempo se puede obtener un elemento de la caché.
P: ¿Qué es el algoritmo óptimo de Belady?
R: El algoritmo óptimo de Belady, también conocido como algoritmo clarividente, es un algoritmo eficiente de almacenamiento en caché que descarta siempre la información que no se necesitará durante más tiempo en el futuro. Por lo general, este resultado no puede aplicarse en la práctica porque requiere predecir lo que se necesitará en un futuro lejano.
P: ¿Cómo funciona LRU (Least Recently Used)?
R: LRU borra primero los elementos utilizados menos recientemente y requiere llevar un registro de qué se utilizó y cuándo mediante el uso de "bits de antigüedad" para cada línea de caché y el seguimiento de cuál se utilizó menos recientemente en función de los bits de antigüedad. Cada vez que se utiliza una línea de caché, las edades de todas las demás líneas de caché se modifican en consecuencia.
P: ¿Cómo funciona MRU (Most Recently Used)?
R: MRU borra primero los elementos utilizados más recientemente y este mecanismo de almacenamiento en caché se utiliza habitualmente para las memorias caché de las bases de datos.
P: ¿Qué otros algoritmos existen para mantener la coherencia de la caché?
R: Existen varios algoritmos para mantener la coherencia de la caché cuando se utilizan varias cachés independientes para datos compartidos, como cuando varios servidores de bases de datos actualizan un único archivo de datos compartidos.
Artículos relacionados
Autor
AlegsaOnline.com Algoritmos de caché: qué son, cómo funcionan y tipos (LRU, LFU, ARC) Leandro Alegsa
URL: https://es.alegsaonline.com/art/15882
Fuentes
- usenix.org : usenix.org/legacy/events/fast03/tech/full_papers/megiddo/megiddo.pdf
- usenix.org : usenix.org