Ley de Zipf: qué es y por qué aparece en palabras, ciudades y empresas
Ley de Zipf: descubre por qué palabras, ciudades y empresas siguen el mismo patrón de distribución y qué implica para el lenguaje, la demografía y la economía.
La ley de Zipf es una ley empírica, formulada mediante la estadística matematica, que lleva el nombre del lingüista George Kingsley Zipf, quien la propuso por primera vez.
La ley de Zipf establece que, dada una gran muestra de palabras utilizadas, la frecuencia de cualquier palabra es inversamente proporcional a su rango en la tabla de frecuencias. Así, la palabra número n tiene una frecuencia proporcional a 1/n.
Así, la palabra más frecuente aparecerá aproximadamente dos veces más que la segunda palabra más frecuente, tres veces más que la tercera palabra más frecuente, etc. Por ejemplo, en una muestra de palabras del idioma inglés, la palabra más frecuente, "the", representa casi el 7% de todas las palabras (69.971 de algo más de un millón). Siguiendo la ley de Zipf, la palabra "of", que ocupa el segundo lugar, representa algo más del 3,5% de las palabras (36.411 apariciones), seguida de "and" (28.852). Sólo se necesitan unas 135 palabras para dar cuenta de la mitad de las palabras de una muestra grande.
La misma relación se da en muchas otras clasificaciones, no relacionadas con la lengua, como los rangos de población de las ciudades de varios países, el tamaño de las empresas, los rankings de ingresos, etc. La aparición de la distribución en los rankings de ciudades por población fue advertida por primera vez por Felix Auerbach en 1913.
No se sabe por qué la ley de Zipf se mantiene para la mayoría de las lenguas.
Galería de imágenes
3 Imágenes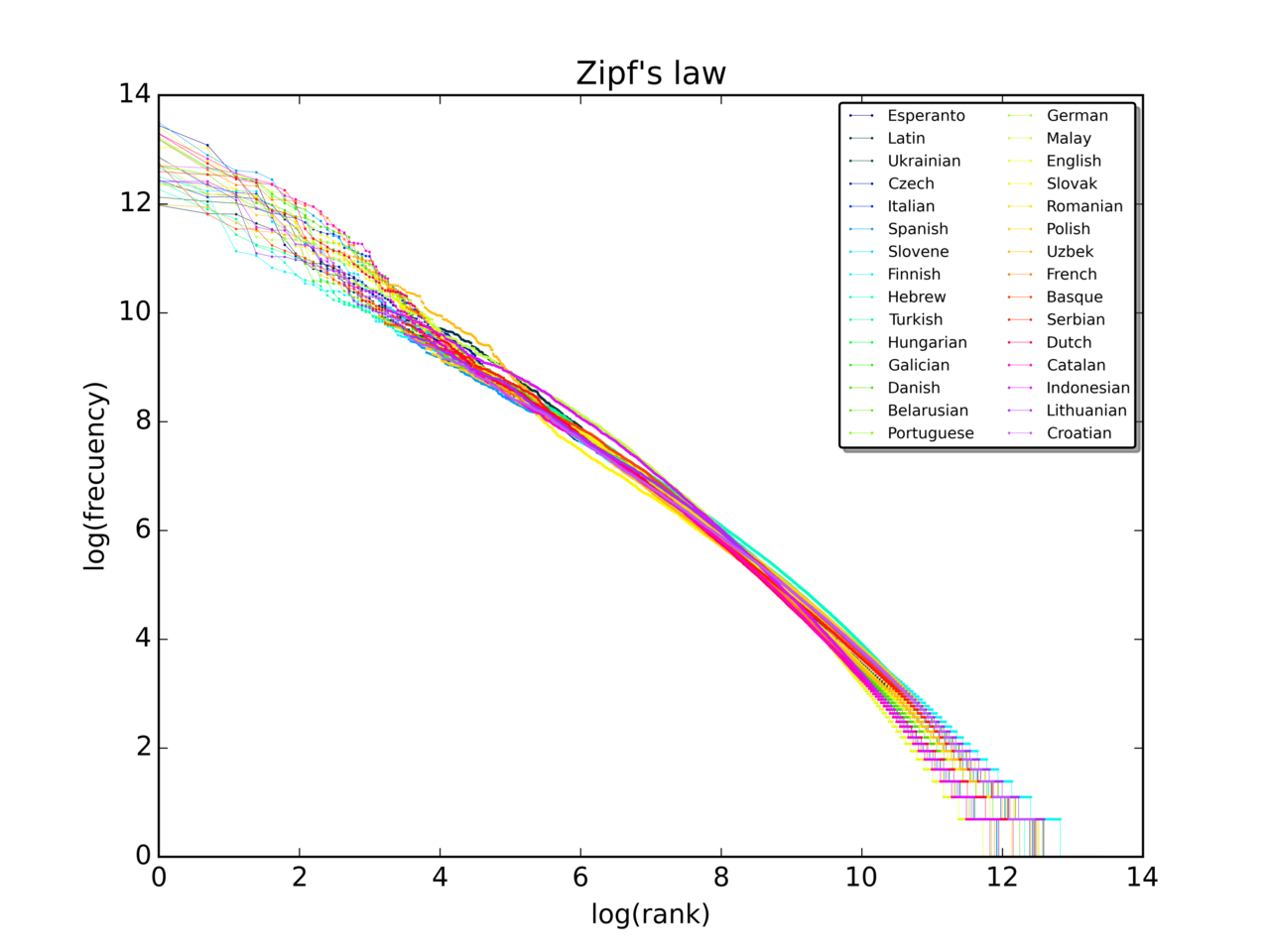


Forma matemática y variantes
En forma general, la ley de Zipf se expresa como f(r) ∝ 1 / r^s, donde f(r) es la frecuencia del elemento con rango r y s es un exponente. En muchos fenómenos observados (especialmente en palabras) s es cercano a 1, lo que lleva a la regla simple f(r) ≈ C / r con una constante de normalización C.
Una variante práctica es la ley de Zipf–Mandelbrot, que añade un corrimiento para ajustar mejor los extremos: f(r) = C / (r + q)^s. Esta forma corrige desviaciones frecuentes en los rangos más altos (palabras o ciudades más frecuentes/grandes).
Ejemplos y alcance
- Lenguas: casi todas las lenguas naturales muestran una distribución aproximada de Zipf para las frecuencias de palabras, aunque los parámetros pueden variar según corpus y tokenización.
- Ciudades: los tamaños de población ordenados por rango suelen seguir una ley de potencias parecida; cuando el exponente es 1 se habla a menudo de la "ley de Zipf para ciudades".
- Empresas e ingresos: el tamaño de empresas (empleo, ingresos) y la distribución de ingresos/riqueza muestran colas pesadas similares a las predichas por leyes de potencias.
- Otras áreas: frecuencias de apellidos, visitas a sitios web, grados en redes complejas y en algunos fenómenos naturales aparecen distribuciones relacionadas.
Por qué aparece: teorías y modelos
No hay una única explicación universal aceptada; distintas teorías describen cómo pueden surgir leyes de potencias y, por tanto, Zipf:
- Principio del esfuerzo: Zipf propuso una explicación basada en un equilibrio entre el esfuerzo del emisor (hablante) por usar pocas palabras y el esfuerzo del receptor por distinguir significados —un compromiso que produce una distribución desigual de frecuencias.
- Modelos de crecimiento preferencial (Simon, Yule): procesos en los que "lo que es popular tiende a volverse más popular" (preferential attachment) generan distribuciones de tipo potencias.
- Modelos aleatorios y de fragmentación: mecanismos multiplicativos y procesos estocásticos con retroalimentación pueden producir colas pesadas.
- Optimización de la información: enfoques desde la teoría de la información y la compresión muestran que ciertos equilibrios entre redundancia y eficiencia conducen a distribuciones cercanas a Zipf.
Limitaciones y cuándo no se cumple exactamente
- La ley es empírica: suele ajustarse de forma aproximada, sobre todo en el rango medio de los datos. Los extremos (primeros rangos y la cola larga) con frecuencia presentan desviaciones.
- El ajuste depende del tamaño y la limpieza del corpus o de los datos: tokenización, eliminación de signos, lenguaje técnico, corpus muy pequeños, etc., influyen mucho.
- Hay fenómenos que presentan potencias con exponentes distintos de 1 o no siguen una ley de potencias en absoluto; por eso es importante estimar parámetros y comprobar el ajuste estadísticamente.
Cómo se prueba y mide
Para verificar Zipf en un conjunto de datos se suelen emplear:
- Gráficas en escala log-log de rango vs. frecuencia: una recta indica una ley de potencias; la pendiente aproxima −s.
- Métodos estadísticos más rigurosos: estimación por máxima verosimilitud del exponente, pruebas de Kolmogorov–Smirnov para comparar con una ley de potencias y análisis de intervalos de confianza.
- Comparación con alternativas (por ejemplo, distribución log-normal, exponencial o Zipf–Mandelbrot) para decidir cuál modelo describe mejor los datos.
Implicaciones prácticas
- Procesamiento del lenguaje natural: la existencia de una pequeña fracción de palabras muy frecuentes motiva estrategias como stop words, modelos de lenguaje que manejan colas largas y técnicas de suavizado.
- Análisis urbano y económico: la ley ayuda a caracterizar desigualdades en tamaños de ciudades o empresas y a generar modelos de crecimiento.
- Diseño de sistemas y búsqueda: conocer la distribución de acceso o uso permite optimizar caches, índices y algoritmos de priorización.
En resumen, la ley de Zipf es una observación robusta y sorprendentemente universal sobre cómo se distribuyen muchos tipos de elementos ordenados por frecuencia o tamaño. Aunque no existe una única causa acordada para todos los fenómenos que la exhiben, la combinación de modelos estocásticos, principios de optimización y efectos de retroalimentación explica por qué las leyes de potencias aparecen con tanta frecuencia en sistemas complejos.
Preguntas y respuestas
P: ¿Qué es la ley de Zipf?
R: La ley de Zipf es una ley empírica que establece que la frecuencia de una palabra en una muestra grande es inversamente proporcional a su rango en la tabla de frecuencias.
P: ¿Quién propuso la ley de Zipf?
R: La ley de Zipf fue propuesta por primera vez por George Kingsley Zipf, lingüista.
P: ¿Cómo explica la ley de Zipf la frecuencia de las palabras en una muestra de palabras inglesas?
R: Según la ley de Zipf, la palabra más frecuente en una muestra de palabras inglesas aparece aproximadamente el doble de veces que la segunda palabra más frecuente, el triple que la tercera palabra más frecuente, etc. Esta tendencia se mantiene a medida que disminuye el rango de la palabra.
P: ¿Qué porcentaje de todas las palabras representa la palabra más frecuente en una muestra de palabras inglesas?
R: En una muestra de palabras inglesas, la palabra que aparece con más frecuencia ("the") representa casi el 7% de todas las palabras.
P: ¿Cuál es la relación entre el número de palabras necesarias para dar cuenta de la mitad de la muestra y la frecuencia de esas palabras?
R: Según la ley de Zipf, sólo se necesitan unas 135 palabras para dar cuenta de la mitad de las palabras de una muestra grande.
P: ¿Qué otras clasificaciones presentan la ley de Zipf?
R: La misma relación que describe la ley de Zipf en la frecuencia de las palabras se da en otras clasificaciones no relacionadas con el lenguaje, como los rangos de población de las ciudades de varios países, el tamaño de las empresas y los rankings de ingresos.
P: ¿Quién se dio cuenta de la aparición de la distribución en las clasificaciones de ciudades por población?
R: La aparición de la distribución en los rankings de ciudades por población fue advertida por primera vez por Felix Auerbach en 1913.
Artículos relacionados
Autor
AlegsaOnline.com Ley de Zipf: qué es y por qué aparece en palabras, ciudades y empresas Leandro Alegsa
URL: https://es.alegsaonline.com/art/110649
Fuentes
- books.google.com : P. 139